
Schneller ETL ist erschwinglich
Mit Voracity gehen Sie über die bisherigen ETL-Tools hinaus
Bei ETL-Operationen (Extrahieren, Transformieren, Laden) werden Daten aus verschiedenen Quellen extrahiert, separat transformiert und in eine Data Warehouse (DW)-Datenbank und möglicherweise andere Ziele geladen.
ETL-Operationen werden oft mit langjährig auf dem Markt befindlichen, einsatzbereiten Tools und manchmal mit kundenspezifischen Inhouse-Programmen durchgeführt. In fast allen Fällen leiden diese Lösungen nach wie vor unter mangelnder Performance im Volumen, der Unfähigkeit, sich an die wachsende Vielfalt, Geschwindigkeit und Zuverlässigkeit der Datenquellen anzupassen, Komplexität und hohen Lizenz- und Supportkosten.
Diese Schwachstellen sind umso deutlicher im Vergleich zur Datenmanagement-Plattform IRI Voracity, die die schnellsten und kostengünstigsten ETL-Operationen in der Data Warehousing-Branche bietet.
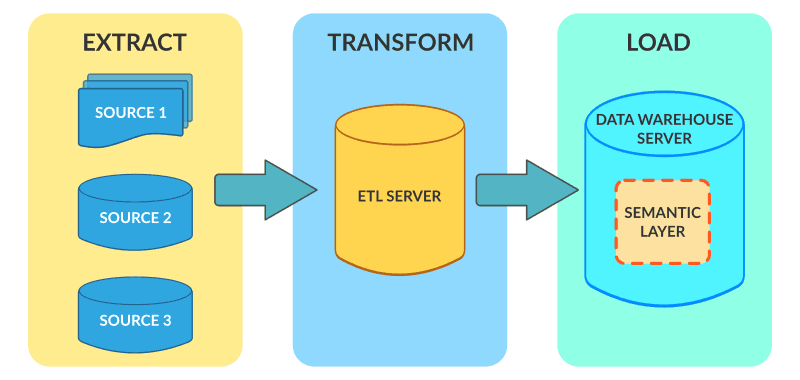
Geschwindigkeit (und Preis) sind entscheidend
Werfen Sie einen Blick darauf, wie Voracity die Operationen Extrahieren, Transformieren und Laden auf einzigartige Weise optimieren und kombinieren kann:
Big Data: Schnelle Akquisition
IRI unterstützt eine Vielzahl von leistungsstarken Extraktionsmethoden für statische Dateien und Streaming-Daten. Pumpen Sie Daten im Speicher über Leitungen oder Verfahren, Webservices, IoT-Geräte, Kafka und mehr.
VLDB-Entladung: ODBC-Auswahl oder "Schnelle Extraktion".
Sehr große Datenbanktabellen (VLDB) erfordern eine leistungsstarke Entlade-(Extraktions-)Methode für:
Data Warehouse ETL- und ELT-Betrieb
Klassische (Offline-)Reorgs
Archivierung und Speicherung
Migration und Replikation
Datenaustausch
IRI Voracity - sowie seine Komponentenprodukte IRI CoSort (für Datentransformation und Reporting), IRI NextForm (für Daten- und Datenbankmigration) und IRI FieldShield (für PII-Klassifizierung und Maskierung) - lesen Daten direkt aus relationalen und NoSQL DBs über ODBC oder native Protokolle. Oder Sie können riesige RDB-Tabellen parallel zu Flat-Files mit IRI FACT (Fast Extract) ausgeben.
Die Extraktionsperformance in DB- und DW-Umgebungen wird durch hohe Datenmengen und ineffiziente Ansätze eingeschränkt. Lesen Sie in diesem Blogbeitrag über ein Mittel gegen große Oracle-Tabellen.
Chirurgisch
Die quellseitige Auswahl in IRI CoSort über SQL und Filterbefehle im CoSort SortCL-Programm sowie Change Data Capture (CDC)-Skripte können die Erfassungsleistung durch Reduzierung der Datenmenge verbessern. SortCL unterstützt eine beliebige Anzahl von Eingabetabellen, Dateien, Pipes und Prozeduren auf einmal und kann für jede Datenquelle spezifische Filterkriterien anwenden.
Sie können auch Werte aus strukturierten und unstrukturierten Dokumentquellen in Flat-Files extrahieren, basierend auf der Suche nach literalen Zeichenketten und Java-Regularausdrücken (Mustern). In der Benutzeroberfläche der IRI Workbench gibt es mehrere Datenentdeckungsassistenten, die auch solche Quellen profilieren, um Ihnen das Auffinden und Verwenden von Dark Data zu erleichtern.
Bulk
Für die VLDB-Datenerfassung verwendet IRI FACT (Fast Extract) native Treiber und parallele Abfragemethoden, um VLBD-Tabellen in Flat-Files zu verwandeln, wenn Massenentladungen erforderlich sind. FACT erzwingt keinen Datenbank-Overhead oder Konfigurationsänderungen. FACT umgeht auch die Notwendigkeit, Log-Sniffer und komplexe CDCs in der Datenbank einzurichten.
FACT verwendet die SQL SELECT-Syntax in einfachen Konfigurationsdateien, um Daten aus: Oracle, DB2 UDB, Sybase, MS SQL Server, MySQL, Altibase und Tibero zu entladen.
Während der Extraktion formatiert FACT die Daten (z.B. Trennzeichen) und konvertiert sie (z.B. Datumstypen) und die LOB-Felder der Silos. FACT schreibt auch CoSort SortCL-Metadaten für Datentransformation, Konvertierung/Replikation, Maskierung und Reporting sowie Metadaten für Laderegler-Steuerdateien für die Quelldatenbanken. Dies erleichtert die Fehlersuche und ETL im gleichen I/O-Pass.
Die IRI Workbench GUI for FACT, CoSort, etc. unterstützt die automatische Erstellung von Tabellen und Ladedateien für zusätzliche Zieldatenbanken einschließlich Teradata - in Eclipse.
Optimieren Sie jede Transformation
Voracity beschleunigt jeden wesentlichen Datentransformationsprozess. Es optimiert auch ETL-Operationen, indem es Sortierungen, Joins und Aggregationen in einem einzigen Jobskript, einer Partition und einem I/O-Pass kombiniert.
Mit Voracity können Sie riesige Datenmengen transformieren, ohne Ihre DB zu verwenden und ohne Hadoop, NoSQL oder eine ELT-Appliance. Besiegen Sie die steilen Lernkurven anderer Tools mit ihren leicht verständlichen, gemeinsamen und modifizierten Daten und Arbeitsplatzdefinitionen.
Voracity hat alles, was Sie brauchen, um Daten schneller und effektiver zu transformieren.
Mehrere Transformationen kombinieren
Voracity ermöglicht es Ihnen, mehrere CPUs und Kerne zu nutzen, mehrere Aufgaben in derselben I/O auszuführen und Ressourcen dynamisch zuzuweisen. Transformieren Sie große Datenmengen aus vielen verschiedenen Tabellen und Quellen gemeinsam. Einfache Textdatei-Metadaten-Repositorys, die Sie in der kostenlosen IRI Workbench GUI auf Eclipse™ verwalten können, ermöglichen es Ihnen, Ihre Daten zu entdecken, zu definieren und freizulegen.
Besiegen Sie die hohen Kosten und Lernkurven anderer Techniken mit den leicht verständlichen, geteilten und modifizierten Metadaten, die Voracity für Daten und Arbeitsdefinitionen verwendet. Wie das zugrunde liegende CoSort SortCL-Program die Datentransformation optimieren und konsolidieren, erfahren Sie im Abschnitt Datentransformation auf der IRI-Website.
Wenn der schnellste Ort zur Bereitstellung einer Data Warehouse Datenbank (DB) im Dateisystem ist, was ist der schnellste Weg sie zu laden? Es gibt viele Möglichkeiten, DBs zu laden, einschließlich:
ein- oder mehrreihige Einsätze
Erstellen oder Einfügen (mit Anhängehinweis) nach Wahl aus einer anderen Tabelle
konventionelle und direkte Weglasten
Viele DBAs kennen nicht die schnellste Methode und verwenden stattdessen proprietäre Export-/Import-Tools, die ihre Datenbanken besteuern und nicht heterogenen Data Warehouse-Architekturen dienen.
Die CoSort-Software in der IRI Data Manager Suite oder der IRI Voracity (ETL)-Plattform kann jede beliebige Datenbanktabelle direkt mit chirurgischen oder Massenmethoden erstellen und füllen.
Die CoSort Datentransformationsphase von Voracity-Aufträgen kann Flat-Files schnell in Indexreihenfolge sortieren, die RDB-Ladeprogramme schnell in Tabellen pumpen können, während sie langsamere, DB-bezogene interne Sortierungen umgehen. Wenn Sie Tabellen in Ordnung haben und den Overhead für die Bulk-Transformation aus der DB-Schicht entfernen, verbessern beide die Abfrageleistung.
Sie können CoSort auch mit oder ohne Voracity verwenden, um große Datenmengen zu transformieren und zu reporten, so dass Ihre DB dies nicht tun muss. Es geht darum, Ihre DB für das freizugeben, was sie am besten kann: Speichern und Abfragen.
Chirurgisch
Verwenden Sie die integrierten ODBC-Funktionen zum Erstellen, Einfügen, Abschneiden, Aktualisieren und Hinzufügen innerhalb von CoSort SortCL Datenpflege- und Mapping-Aufträgen, während Sie Ihre Ziele definieren. Oder verwenden Sie direkte DB-Verbindungen und SQL-Funktionen, die in die Eclipse IRI Workbench GUI integriert sind und CoSort, Voracity, FieldShield (Datenmaskierung), NextForm (Daten/DB-Migration) usw. unterstützen.
Bulk
Voracity ETL und andere neue Assistenten für die Auftragserstellung in der IRI Workbench bieten eine automatische Tabellenerstellung und die Generierung von Ladersteuerungsdateien für Altibase iLoader, DB2 UDB load, Oracle sqllder, SQL Server und Sybase bcp sowie Teradata Fast und Multiload. Auf diese Weise können Sie die schnellste Methode zum Massenladen von relationalen DBs.... vorsortierten Dateien nutzen. Siehe diesen Artikel über High Speed DB Loading.
Die Vorteile von Voracity
Klicken Sie auf die untenstehenden Kästen, um zu erfahren, warum Voracity eine bessere Alternative für den ETL-Betrieb und darüber hinaus ist:
Geschwindigkeit
IRI FACT (Fast Extract) verwendet native Treiber, um große Tabellen parallel zu Flat-Files oder Pipes zu entladen.
IRI CoSort übernimmt die Ausgabe von FACT aus einer Datei oder einem In-Memory-Stream (Pipe) und übernimmt das die Datentransformation, die Lastvorsortierung und das Reporting im selben Jobskript und I/O-Pass.
Die Plattform IRI Voracity für totales Daten-Management kombiniert FACT, CoSort und Bulk DB Load Utilities in einem visualisierten, geplanten ETL-Workflow, der weder kompiliert noch partitioniert werden muss. Es kann sogar CoSort-Aufträge in MapReduce, Spark, Storm oder Tez nahtlos ausführen.
Vergleichen Sie all dies mit langsameren, umfangreicheren SQL- und 3GL-Programmen und mit teureren, komplexeren ETL- und ELT-Plattformen.... ganz zu schweigen von den Verzögerungen beim Onboarding von disjunkten Apache-Projekten.
Einfachheit
ETL-Metadaten und Jobdefinition werden in der IRI Workbench GUI für Voracity, die auf Eclipse™ basiert, automatisiert. Datenentdeckungs- und neue Jobassistenten sowie eine Reihe visueller ETL-Jobdesign-Optionen, schnellere Erstellung wiederverwendbarer Repositories und Skripte, ohne dass eine Schulung in neuer Syntax erforderlich ist.
Dennoch sind Voracity-Metadaten die am einfachsten zu erlernenden und zu verwendenden in der IT-Branche. Es verwendet die gleiche menschenlesbare 4GL von CoSort - genannt SortCL -, die die vertraute Datenlayout-Syntax, SQL-Manipulationskonzepte und gemeinsame Metadaten-Repositorys nutzt. Viele Benutzer bevorzugen es immer noch, diese einfachen Skripte direkt zu kodieren und zu optimieren.
Vielseitigkeit
Die Voracity ETL-Umgebung unterstützt nicht nur extrem schnelle Extraktion/Ladung und One-Pass-Datentransformationen, die keine Partitionierung erfordern:
Datenerfassung ändern
Suche/Extrahieren/Struktur von dunklen Daten
Datenbank- und Dateiprofilierung
Datenmaskierung, Verschlüsselung, etc.
Datenmigration und -replikation
Erstellung, Konvertierung und Freigabe von Metadaten
Detail- und Zusammenfassungsberichte
Stammdatenmanagement (grundlegend)
Metadatenmanagement & Lineage
Offline-Reorgs
Langsam wechselnde Abmessungen
Testdatengenerierung
Datenbank-Subsetting
Datenqualität (Cleansing, Deduplizierungsprüfung, Vereinheitlichung, Standardisierung)
Voracity unterstützt diese Aktivitäten auf einer sehr breiten Palette von strukturierten, älteren, großen Daten-, Cloud- und SaaS-Datenquellen.
Ergonomie
Erstellen Sie alle E-, T- und L-Jobs in der IRI Workbench GUI for Voracity, die auf Eclipse™ basiert. Bearbeiten Sie die Aufträge oder den Workflow in Paletten, GUI-Dialogen, syntaxfähigen Skript-Editoren (oder einem beliebigen Texteditor, den Sie bevorzugen) oder im AnalytiX DS Mapping Manager. Sie haben die ergonomische Flexibilität, die Datendefinitionen und Manipulationen visuell oder durch Skripting zu bearbeiten; alles was in dem einen getan wird, füttert den anderen.
Testen oder Ausführen von Jobs einzeln oder gemeinsam im GUI-Flow oder später in einem (geplanten) Batch-Betrieb. Sie haben diese Flexibilität bei der Ausführung, da die Jobskripte portabel sind. Sie können jeden der Teile oder das gesamte Projekt auf jeder Plattform ausführen, auf der die Engine(s) lizenziert sind. Rufen Sie sie von der Kommandozeile oder einer beliebigen Anwendung aus auf.
Erweiterbarkeit
Die IRI Workbench GUI für Voracity bietet die visuellen Werkzeuge zur Erstellung, Konvertierung und Erkennung von Metadaten, die Sie benötigen um Jobskripte, Datendefinitionsdateien (DDF) und XML-Workflows zu generieren, bereitzustellen und zu verwalten, die in allen IRI-Softwareprodukten gleich sind.
An der gleichen Stelle können Sie auch COBOL, C/C++, Hive, Impala, Java, Perl, Python, R, SQL und andere von Eclipse unterstützte Programme entwerfen und ausführen und sie manchmal als Schritte in Ihren Voracity-Workflow integrieren.
Sie können das Programm SortCL von CoSort in Voracity auch verwenden, um Transformationen für andere ETL-Tools wie Informatica und DataStage zu optimieren.
Ökonomie
Voracity ist weit mehr als ein ETL-Tool, aber der Preis liegt unter den meisten von ihnen. Selbst wenn Sie es nicht für ETL verwenden, da sein SortCL-Programm über viele Quellen hinweg zusammengefügt werden kann und Daten in Flat-Files abfragen kann, setzt Voracity die CoSort-Tradition als eine der kostengünstigsten Methoden zur Datenerfassung von Änderungen (CDC) und NoSQL-Abfragen fort.
Für ernsthafte ETL-Architekten ist Voracity jedoch durch die Konsolidierung und Mehrfachverarbeitung von Transformationen im Dateisystem oder (nahtlos in) Hadoop die kostengünstigste Alternative zur Verarbeitung großer Datenmengen zu DB/ELT-Appliances, Ab Initio, SyncSort, Teradata und In-Memory-DBs.
Schließlich ist Voracity mit seinen Freemium-Editionen, seinen kostengünstigen Opex-Abonnement-Tiers und seiner relativen Einfachheit die günstigste Datenmanagement-Plattform, die es zu nutzen und zu warten gilt.
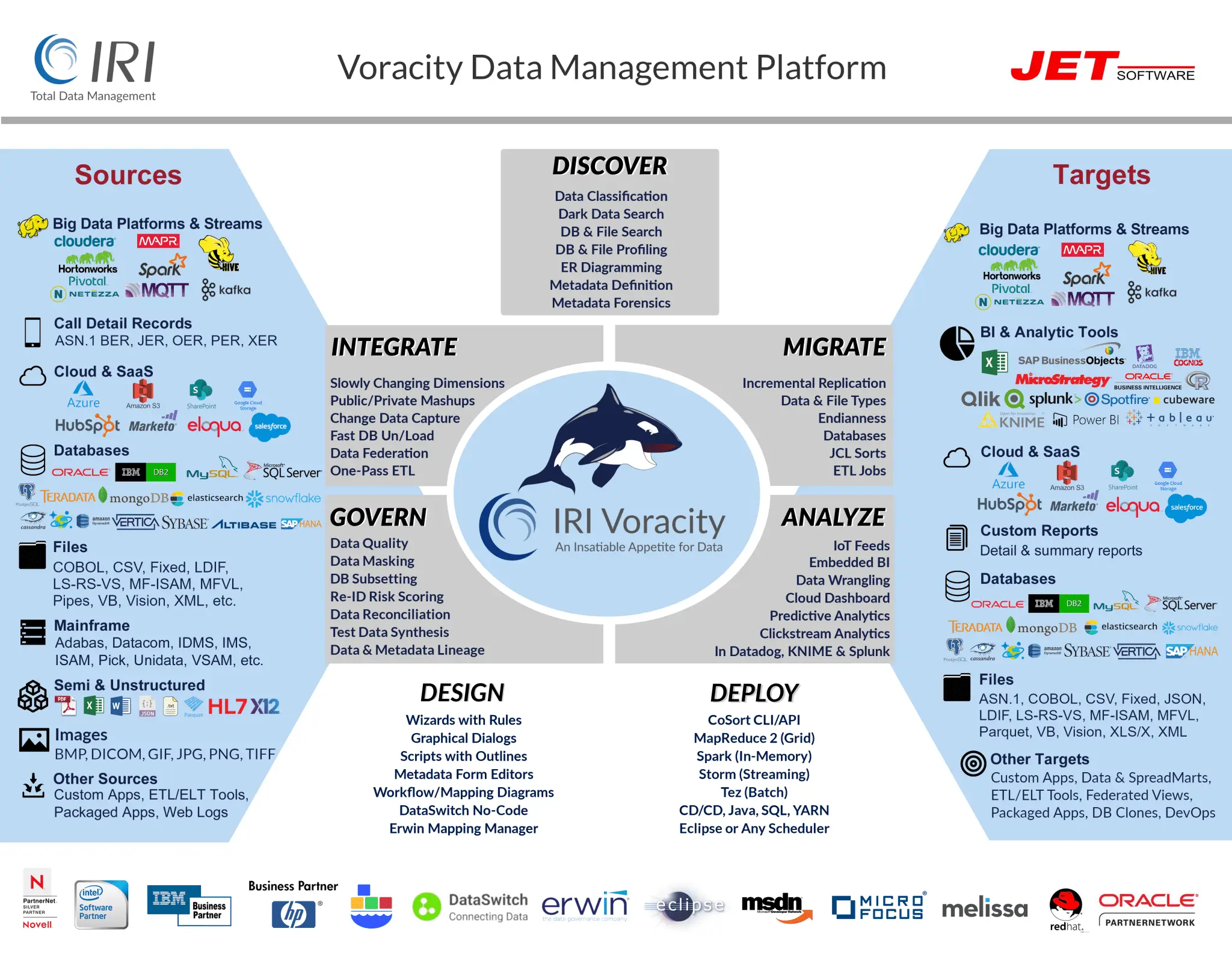
Verwandte Lösungen