
Datenanonymisierung
Hinzufügen von Rauschen oder Allgemeingültigkeit zu PII
Verwischen und Bucketing
Indirekte Identifikatoren oder "quasi identifizierende Werte" wie Alter und Geburtsdatum sowie Deskriptoren wie Beruf und Familienstand können alle verwendet werden um Personen neu zu identifizieren, wenn genügend dieser Attribute im Datensatz vorhanden sind und/oder sie zu einer Obergruppe mit ähnlichen Werten zusammengefasst werden können.
Aus diesem Grund können Ihre Jobs im IRI FieldShield Datenmaskierungsprodukt (oder der IRI Voracity Datenmanagement-Plattform) eine oder mehrere zusätzliche Techniken anwenden, um diese Datenwerte zu anonymisieren und gleichzeitig realistisch und genau genug für Forschungs- oder Marketingzwecke zu halten. Numerische Unschärffunktionen erzeugen zufälliges Rauschen für bestimmte Alters- und Datumsbereiche. Bucketing-Funktionen, die die Werte in breitere Kategorien verallgemeinern, anonymisieren auch Quasi-Identifikatoren.
In der untenstehenden exemplarischen Stellenbeschreibung werden bestimmte Altersgruppen in Dekadengruppen eingeteilt, mehrere Familienstandsattribute werden in einem definierten Zustand in zwei breitere Kategorien zusammengefasst, Bildungsabschlüsse werden durch eine neue Set-Lookup-Datei vereinfacht und alle Berufe wurden explizit neu bearbeitet.
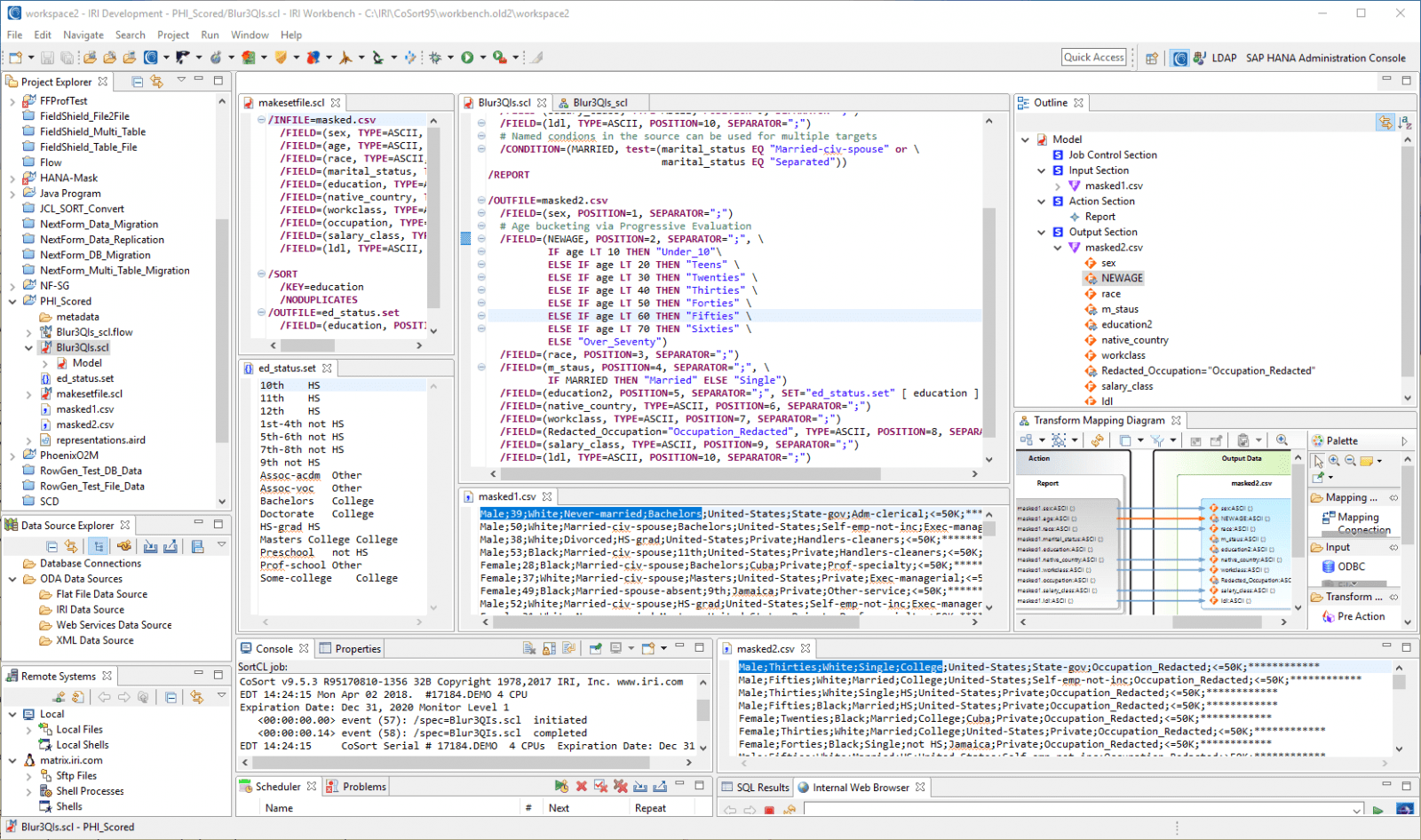
Diese Job-Spezifikationen können in zweckmäßigen grafischen Assistenten und funktionsspezifischen Dialogen automatisch generiert werden. Die neue Ergebnismenge kann nun durch den Risiko-Scoring-Assistenten erneut ausgeführt werden, um eine weitere Bestimmung des Re-Identifizierungsrisikos basierend auf nun weniger ausgeprägten quasi-identifizierenden Attributen zu erhalten.