
Datenreplikation - Lösungen
Erfassen, Manipulieren, Kopieren - schneller, einfacher, günstiger
Die IRI-Software ist eine führende Lösung im Bereich der Datenreplikation, die Ihnen hilft, Daten aus heterogenen Datenquellen schnell und kostengünstig zu manipulieren und zu synchronisieren. Mit dieser fortschrittlichen Datenreplikationstechnologie können Sie regelmäßige, frische Kopien von Daten für Tests, Berichte oder andere Anwendungen verwenden.
Replizieren Sie riesige Mengen an relationalen Datenbanken, Mainframe-Datensätzen, Flat-Files und anderen sequentiellen Datenquellen in Echtzeit oder im Batch mit Hilfe von Software in der IRI Workbench GUI, die auf Eclipse™ basiert. Diese Datenreplikationstechnik sorgt für eine nahtlose und effiziente Übertragung Ihrer Daten.
Welche Datenreplizierungsmethode Sie auch immer mit IRI wählen, die Software zeichnet
sich durch ihre Kompetenz in der Datenreplikation aus und ist:
· Skalierbar im Volumen (über Multi-Threading und Task und I/O-Konsolidierung)
· Datenbank- und Plattformunabhängigkeit
· Zuverlässig in Bezug auf die Daten- (und referentielle) Integrität
· Funktionell flexibel, ob im Batch oder in Echtzeit
· Preiswerter und einfacher zu bedienen als Replikations-Software wie GoldenGate
Beispiele der Datenreplikation
Haben Sie eine einzige Datenquelle, die für die Datenreplikation in einem anderen Format neu gegossen werden muss? Um die Daten in einer nicht-relationalen COBOL-Indexdatei in eine CSV-Datei für Excel oder ein anderes relationales Ziel zu kopieren, nutzen Sie die Fähigkeiten von IRI NextForm in der Datenreplikation. Siehe dieses einfache Beispiel.
Haben Sie einen einfachen Replikationssatz oder ein Datenbank-Subset, die Sie für die Datenreplikation benötigen und an andere Benutzer weitergeben müssen? Verwenden Sie dazu IRI CoSort oder IRI FieldShield (oder die größere IRI Voracity-Datenverwaltungsplattform, die diese enthält) und maskieren Sie gleichzeitig persönlich identifizierbare Informationen (PII).*
Replizieren Sie mehrere Quellen (wie relationale oder NoSQL DB-Tabellen) auf einmal, geben Sie sie an mehrere Schemata oder andere Ziele aus oder führen Sie unterwegs ähnliche Manipulationen durch:
· Deduplizierung und Auswahl
· Aufteilen, Zusammenführen von Datenelementen
· Bereinigung, Anreicherung und Validierung
· Änderungsdatenerfassung (CDC)
· Normalisieren oder Denormalisieren
· Sortieren, Join und Aggregation
· Datenmaskierung, Verschlüsselung usw.

Sie können die oben genannten Aufgaben ausführen und zu einem oder mehreren Jobs kombinieren, die in zweckmäßigen Assistenten und ETL-Workflows in Voracity definiert sind. Führen Sie diese Transformationsjobs während der Replikation in Voracity "on the fly" aus und als Datenmaskierungsskripte, die z.B. neben DB-Klonierungsoperationen in Commvault, Windocks und Actifio laufen.
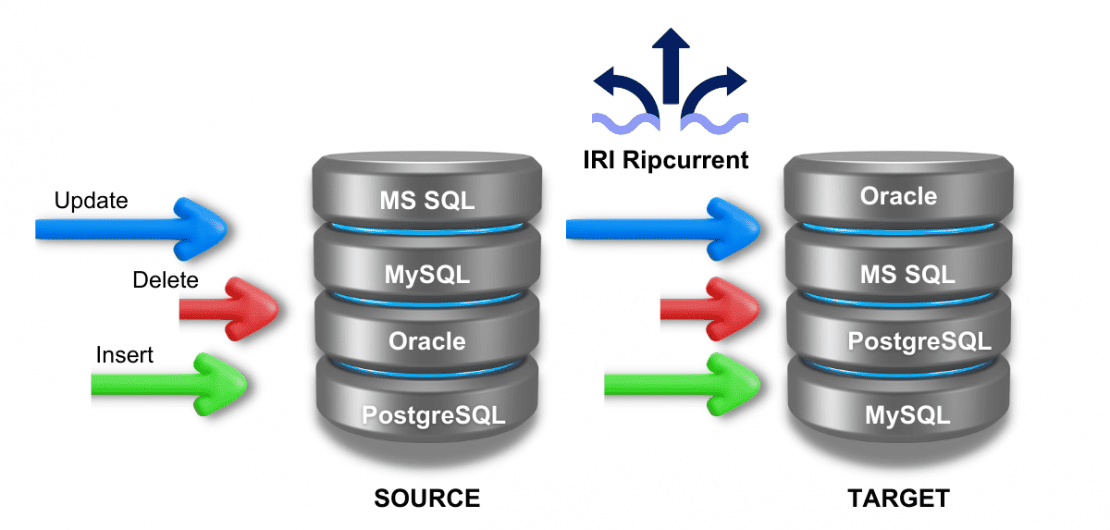
Nutzen Sie die IRI Ripcurrent-Echtzeit-Änderungsdatenerfassung in IRI Voracity, um Daten inkrementell zu aktualisieren, zu maskieren, zu bereinigen, zu transformieren oder zu berichten, wenn MS SQL-, MySQL-, Oracle- und PostgreSQL-Datenbankzeilen eingefügt, aktualisiert oder gelöscht werden, oder um Sie zu benachrichtigen, wenn sich ihre Struktur ändert.
Andernfalls können Sie auch ereignisgesteuerte Trigger vor den Aufträgen einfügen oder nach Zeitstempel- oder ID-Spaltenwerten filtern, um nur die neueren Zeilen zu replizieren, wie in diesem Beispiel zwischen Oracle und MongoDB.
Entwerfen, Ausführen und Verwalten der Mappings in (und Versionen von) diesen Projekten in der kostenlosen IRI Workbench IDE für Voracity et al, die auf Eclipse aufbaut. Stellen Sie die resultierenden, selbstdokumentierenden Job-Skripte auf jeder Plattform bereit. Senden Sie die Ergebnisse direkt an Ihre Ziele, Federationsquellen oder einen Replikationsserver.
Sie können sogar die von Ihnen erstellten Output-Mappings zur automatischen Definition neuer Tabellen-Metadaten und zum Laden von Utility-Konfigurationsdateien verwenden, um Ihre Ziele mit vorsortierten Daten zu füllen!
*Um Testdaten in jedem Format bereitzustellen, ohne auf Produktionsdaten zuzugreifen oder diese zu replizieren, verwenden Sie IRI RowGen.