
Werfen Sie einen genaueren Blick auf Voracity
Innerhalb der Leistungsfähigkeit der Plattform
Volumen

Datenquellen aus internen und öffentlichen Quellen wachsen exponentiell.
Vielfalt

Die Vielzahl der strukturierten und unstrukturierten Quellen übersteigt die meisten Werkzeuge.
Können Ihre Tools die Lasten von Morgen bewältigen?
Bereiten Sie große Datenmengen schnell für Analysen vor, indem Sie Transformationen in Ihrem Dateisystem beschleunigen und kombinieren - nicht in der BI- oder DB-Schicht. Nutzen Sie Voracity, um Daten in einem Durchgang zu de-duplizieren und zu filtern, zu sortieren und zu verbinden, zu aggregieren und zu segmentieren, neu zu formatieren und zu verarbeiten. Erstellen Sie im Rahmen des Prozesses auch Berichte mit eingebetteter BI. Oder senden Sie aufbereitete Daten im Speicher in Echtzeit an BIRT, Datadog, KNIME oder Splunk oder in Cubes, die Ihre Anwendung benötigt. Andernfalls können Sie die aufbereiteten Flat-Files oder RDB-Ansichtstabellen zur Verwendung in diesen Tools sowie in Business Objects, Cognos, Cubeware, iDashboards, Microstrategy, OAC/OBIEE/ODV, PowerBI, QlikView, R, Splunk, Spotfire oder Tableau weitergeben und so die Zeit bis zur Anzeige verkürzen.
Können Sie interne und externe Quellen an einem Ort erwerben und zusammenfassen?
Welche Werkzeuge verwenden Sie jetzt um alle Daten, die Sie sammeln oder kaufen, zu entdecken, zu extrahieren, zu verarbeiten und zu analysieren? Können Sie das alles in einer Konsole erreichen und verarbeiten? Können Sie die Metadaten und Stammdaten an einem Ort kontrollieren und verwalten? Können Sie die Daten auch dort analysieren oder zumindest schnell integrieren und für externe Anwendungen vorbereiten? Wenn Sie mehrere Tools verwenden, können Sie das erforderliche Fachwissen verwalten? Oder wenn Sie eine ältere ETL-Plattform verwenden, können Sie die Kosten dafür tragen?
Die CoSort Engine in Voracity verarbeitete große Daten, lange bevor sie als Big Data bezeichnet wurde und führte und kombinierte Multi-Gigabyte-Transformationen in Sekundenschnelle durch, wobei sie die Sortier-, BI-, DB- und ETL-Tools von Drittanbietern um das 2-20fache verbesserte. Und als IRI im Jahr 2018 40 Jahre alt wurde, erklärte der DW-Branchenguru Dr. Barry Devlin Voracity zur produktiven Analyseplattform. Erfahren Sie hier warum.
Und jetzt gibt es auch Hadoop-Optionen in Voracity, die riesige Workloads über MapReduce 2, Spark, Spark Stream, Storm und Tez auf gängige Hardware verteilen und skalieren.
Voracity analysiert, integriert, migriert, regiert, profiliert und verbindet sich mit rund 150 verschiedenen Datenquellen und Zielen... strukturiert, teilstrukturiert und unstrukturiert.
Dazu gehören ältere Dateien, Daten und Endiant-Typen sowie gängige flache Dateiformate und Dokumentformate, jedes RDBMS und neuere Big Data- und Cloud/SaaS-Quellen.
Geschwindigkeit
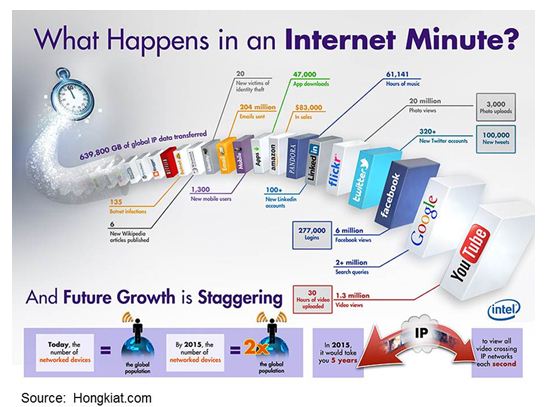
CDR-, IoT-, Sozial- und andere Daten kommen schnell und in unterschiedlichen Abständen.
Wahrhaftigkeit
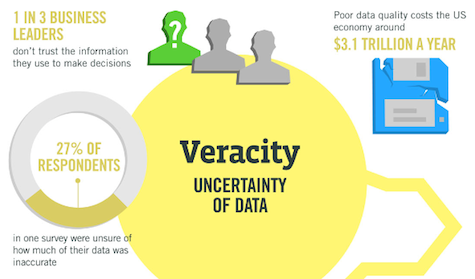
Niedrige Datenqualität gefährdet Apps und Analysewerte. PII ist ein weiteres Datenrisiko.
Sind Sie bereit für Streaming, Echtzeit- und Batch-Daten?
Die größten Datenmengen werden immer noch in regelmäßigen Batch-Zyklen verarbeitet, was die nativen Voracity-Optionen CoSort und Hadoop MapReduce und Tez optimieren wird. Aber was ist mit der Notwendigkeit, Daten in Echtzeit zu verarbeiten (transformieren, maskieren, neu formatieren) und zu analysieren, um sofortige Werbekampagnen durchzuführen (denken Sie an mobile Geräte) oder Warnmeldungen (wie Verkehrs- und Wetterhinweise), die Fahrern oder Besuchern von Veranstaltungen helfen können?
Wie erhalten Sie die Zuverlässigkeit und Sicherheit Ihrer Daten?
Müll rein = Müll raus, und damit Daten im Zweifel. Die Datenqualität leidet unter inkonsistenten, ungenauen oder unvollständigen Werten. Social-Media-Daten können irreführend sein, unstrukturierte Daten ungenau und Datenmehrdeutigkeiten plagen MDM. Umfragedaten können verzerrt, verrauscht oder anormal sein. Inzwischen müssen PII und Geheimnisse, die in all diesen Daten enthalten sind, vor der gemeinsamen Nutzung maskiert werden. Haben Sie einen zentralen Kontrollpunkt, um Daten zu bereinigen und sicher zu machen?
Voracity beinhaltet CoSort zur Integration von Daten in Speicher und Dateien, so dass Sie große Daten 6x schneller als ETL-Tools, 10x schneller als SQL und 20x schneller als BI/Analyse-Tools verarbeiten können. Sein typischer Modus, einschließlich CDC, ist Batch.
Voracity kann Echtzeit-, Echtzeit- und Streaming-Daten über Kafka- oder MQTT-Broker, im Speicher über Pipes oder Eingabeverfahren an CoSort oder in Hadoop Spark oder Storm-Engines verarbeiten.... alles aus derselben Eclipse-GUI, IRI Workbench. Weitere Optionen sind die Verwendung des integrierten Job Launcher, um Voracity-Aufträge in nahezu Echtzeit zu erstellen, oder die Verwendung spezieller BAM- oder CEP-Tools zur Verwaltung ereignisgetriebener Aktivitäten.
Die Datenentdeckungs-, Fuzzy-Matching-, Wertvalidierungs-, Scrubbing-, Encrichment- und Vereinheitlichungs-Funktionen von Voracity verbessern die Datenqualität.
Die umfassenden Datenmaskierungsfunktionen von Voracity und die Möglichkeit zur Generierung synthetischer Testdaten verhindern das Risiko von Datenverstößen und schlechten Prototypen.
Wert
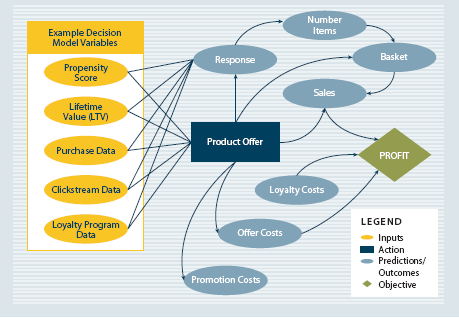
Und der Sinn des Ganzen.... analytischen Wert aus großen Daten zu gewinnen.
Bekommst Sie die Erkenntnisse, die Sie brauchen um Entscheidungen zu treffen?
Überlegen Sie, welche Informationen und Entscheidungen Sie aufgrund von Daten benötigen. Verfolgen Sie beispielsweise das Verbraucherverhalten, Wettermuster, Geräte- oder Webprotokollaktivitäten, um Werbeaktionen zu ändern, Vorhersagen zu treffen oder Probleme zu diagnostizieren? Sehen Sie den Wert einer IDE, die einfach genug für die Datenvorbereitung und -präsentation im Selbstbedienungsmodus ist, aber auch leistungsfähig genug für die Zusammenarbeit von IT- und Geschäftsanwendern beim Datenlebenszyklusmanagement? Und wenn Sie BIRT, KNIME oder Splunk verwenden, können Sie die Daten in diese Strukturen übertragen, während sie verarbeitet werden?