
Pivot / Unpivot
Entnormalisieren und Normalisieren von Zeilen und Spalten
Normalisierte Zeilendaten- und Spaltendarstellungen können eine Verdichtung zu einem de-normalisierten Layout erfordern, indem Zeilen in Spalten gedreht werden. Dies ist eine häufige Anforderung in statistischen tabellenübergreifenden Berichten. Um effizient zu schwenken und doppelte Zeilen zu vermeiden, sollten die Daten vorsortiert werden. In anderen Tools ist dieser Schritt separat und langsam bei großem Volumen.
Die Normalisierung von de-normalisierten Inhalten oder unpivotisiertem Inhalt stellt andere Probleme dar. Beispielsweise können Zeilen unerwartete Werte haben oder ganz fehlen, wenn die Spaltenwerte Null sind oder Null waren. Die Sortierung nach ist getrennt.
SQL-Pivot- und Un-Pivot-Befehle, sofern verfügbar, sind nicht immer einfach oder portabel für Datenbanken. ETL-Tools können komplexe Aggregat- oder Unionstransformationen (mit "Ports" und "Expressions") oder spezifische Pivot/Unpivot-Transform-Editoren mit vielen zu konfigurierenden Eigenschaften erfordern.
SQL CrossTab-Skripte sind ebenfalls klobig und nützen nichts, um Felder und Datensätze in eine Flat-File neu zuzuordnen. XSL "for-each" Transformationen in Flat-XML-Dateien sind noch komplexer. Dann stellt sich die Frage, wie sich all diese Methoden im Volumen verhalten.
Lösungen
Das Programm SortCL im IRI CoSort Paket oder der IRI Voracity Plattform transponiert Zeilen und Spalten und unterstützt gleichzeitig weitere Transformations-, Bereinigungs-, Maskierungs- und Berichtsfunktionen. Sie können Pivot- und Un-Pivot-Operationen über einen ergonomischen Job-Assistenten in der IRI Workbench GUI und/oder ein einfaches 4GL-Job-Skript definieren.

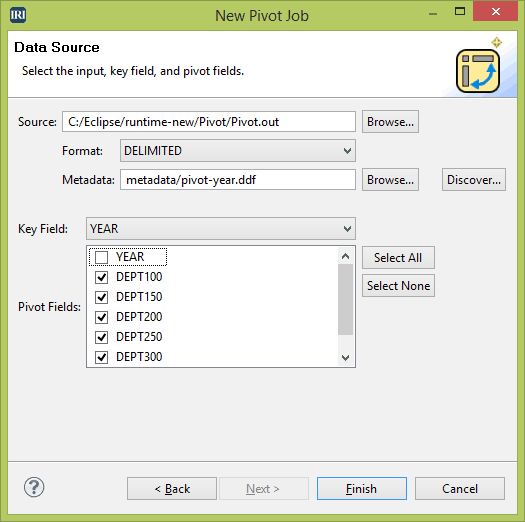
Der neue Pivot-Job-Assistent in der IRI Workbench führt Sie durch die notwendigen Spaltenspezifikationen für jede Datenquelle.
Der gleiche Assistent kann auch für Unpivot verwendet werden....
Andere Ressourcen