Testdatenautomatisierung
Testdatenmanagement in DevOps
Herausforderungen
Anwendungen und Datenbanken haben ihre eigene Logik und einzigartigen Eigenschaften. Damit Testdaten in diesen Kontexten nützlich sind, müssen sie Produktionsmerkmale widerspiegeln, wie z.B:
- Auswahlbedingungen (Geschäftsregeln)
- Spaltenattribute und Transformationen
- Inter-Feld/Schlüssel-Beziehungen (referentielle Integrität)
- Wertebereiche und spaltenübergreifende Berechnungen
Auch Testdaten zur Produktionsqualität müssen diese Attribute aufweisen:
- Typ - korrekte Spalten-/Feldwerte und Formate
- Breite - Werte mit aktuellen (und zukünftigen) Bereichen
- Häufigkeit - realistische Muster des Auftretens von Werten
- Tiefe - Volumina, die Skalierbarkeitsprobleme ansprechen
In einer schnelllebigen DevOps- und Continuous Integration (CI)/ Continuous Deployment (CD)-Umgebung kann die Fähigkeit, konsistente und realistische Testsätze zu generieren und zu automatisieren, die in Format und Umfang sehr unterschiedlich sein können, eine große Herausforderung darstellen und Programmierer mit engen Lieferfristen ablenken.
Lösungen
Anwendungen, die mit realistischen Datenformaten und -mengen entwickelt werden, haben in der Produktion eher Aussicht auf Erfolg. Das IRI RowGen-Paket zur Erstellung von Testdaten verwendet Produktions-Metadaten, um benutzerdefinierte Testsätze mit zufällig generierten Daten und/oder zufällig ausgewählten Daten aus Produktionsquellen zu synthetisieren. Die Datenmaskierungssoftware IRI FieldShield und IRI DarkShield kann auch verwendet werden, um sensible Daten in der Produktion zu finden und zu maskieren und maßgeschneiderte Ziele in niedrigere Testumgebungen zu verschieben.
Um die richtigen Werte und Wertebereiche zu erzeugen, verwendet RowGen bedingte Auswahl- und Formatierungsparameter. RowGen erhöht die Realitätsnähe der Testdaten durch referenzielle Integrität, Häufigkeitsverteilungen und integrierte Transformations- und Formatierungsfunktionen. So können Sie beispielsweise Daten nach dem Zufallsprinzip auswählen und Bereiche aus Pools echter Daten bzw. gewichteter Zahlen festlegen.

Für Continuous Integration und Continuous Deployment or Delivery (CI/CD)-Umgebungen kann RowGen Testdaten in jedem Schritt eines Entwicklungsprozesses synthetisieren, ohne auf die Bereitstellung von Daten aus einem anderen Schritt angewiesen zu sein. Darüber hinaus und auf einzigartige Weise können eingebettete Datentransformations-, Validierungs- und Formatierungsfunktionen gleichzeitig mit den generierten Daten im selben Skript ausgeführt werden! Dies kann inkrementelle Anwendungstests erleichtern, die Rückwärtskompatibilität und Vorwärtskompatibilität mit Ihren Produktionsversionen sicherstellen. Siehe diesen Anwendungsfall.
Kombinieren Sie zufällige Generierung und Auswahl von Set-Dateien, Bedingungen und Manipulationen auf Feldebene und benutzerdefinierte Layout-Funktionen. Erstellen Sie schnell die intelligenten Daten, die Sie zum Stresstest und zur Überprüfung Ihrer Anwendungen benötigen. Verbessern Sie die Qualität und Zuverlässigkeit Ihrer Ergebnisse. Planen Sie Jobs zur Wiederholung von Generierungs- und Testvorgängen in der IRI-Workbench (oder Ihrem eigenen CLI-unterstützenden Automatisierungstool), um CI- und CD-Prozesse zu glätten.
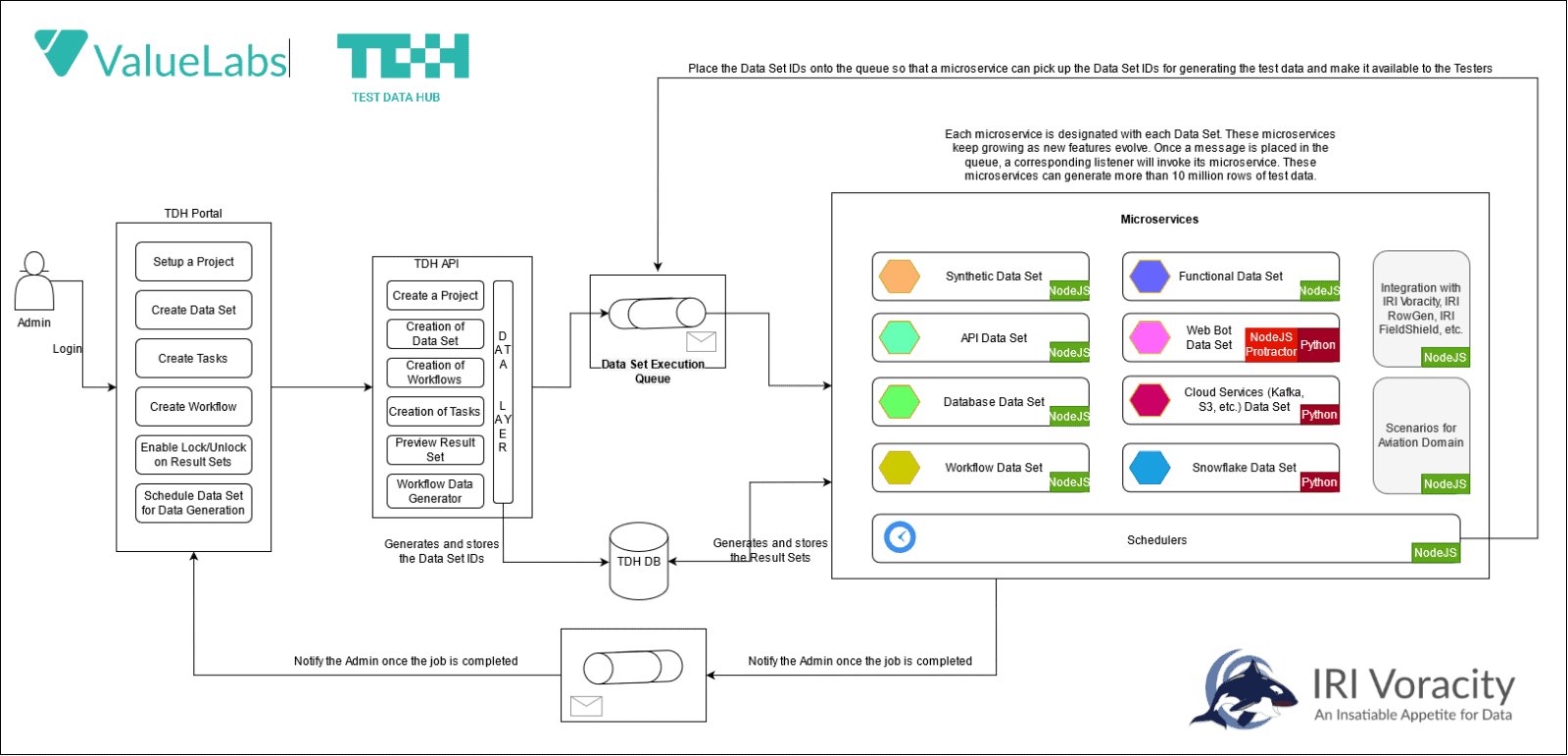
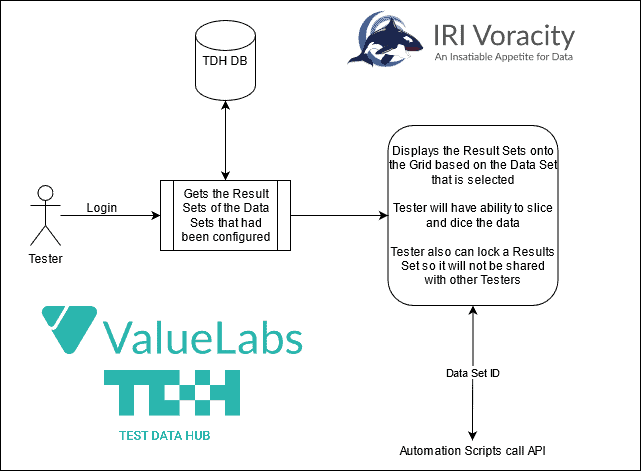
Wenn Sie es immer noch vorziehen, mit Daten zu testen, die sich in Produktions-DBs befinden, können Sie auch RowGen verwenden, um sie schnell zu unterteilen. Oder Sie können mit IRI FieldShield und IRI DarkShield eine noch breitere Palette von Quellen maskieren. Wenn Sie mehrere Funktionen benötigen oder Testdaten aus einer Vielzahl von statischen oder Streaming-Quellen virtualisieren müssen, sollten Sie sich die IRI Voracity Datenmanagement-Plattform und Partner wie Value Labs und deren Voracity-unterstützenden Test Data Hub ansehen, der Testdaten auf Abruf bereitstellt.
Und wenn Sie bestehende CI/CD-Pipelines verwenden, können Sie die IRI-Software direkt aufrufen, um maskierte, subsettierte oder synthetisierte Daten für diese bereitzustellen! Sehen Sie sich die Beispiele der Testdatengenerierung für DevOps an, die in: Amazon CodePipeline, Azure DevOps, GitLab und Jenkins. Wenn Sie ein anderes Framework zur Testdatenautomatisierung verwenden, fragen Sie uns danach!
Verwandte Lösungen
Produktlinks