
Datenbank-Subsetting
Test mit kleineren, maskierten Schemas
Herausforderungen
Entwickler von Datenbankanwendungen verlassen sich zum Testen oft auf Daten in Produktionstabellen. Aber es gibt mehrere Nachteile dieses Ansatzes, einschließlich der:
1. Vertraulichkeit der Daten in diesen Tabellen
2. Kosten für die Migration, Maskierung, Aktualisierung und/oder Speicherung replizierter Datenbanken zum Testen
3. Redundanz der Produktionsdaten, was zu Platzverschwendung und unzureichender Testabdeckung führt
4. nur kleine Datenmengen für spezifische Testfälle benötigt werden
Lösungen
Zusätzlich zu den leistungsstarken Funktionen zum Parsen, Generieren und Populieren von Datenbanken die IRI RowGen für die Synthese von strukturell und referenziell korrekten Testdaten bereitstellt, können Sie nun auch Datenbank-Subsets erzeugen (und maskieren).
Ein leistungsfähiger Datenbank-Subsetting-Assistent ist nun in der IRI Workbench GUI für Benutzer der IRI Voracity-Plattform oder der IRI Datenschutz Suite-Software (einschließlich IRI FieldShield und/oder RowGen) verfügbar. Dieses ergonomische Dienstprogramm ermöglicht es Ihnen, schnell überschaubare Mengen zuverlässiger und referenzfreier Daten aus Produktionstabellen zu erstellen und gleichzeitig Maskierungs- und Abbildungsregeln anzuwenden.
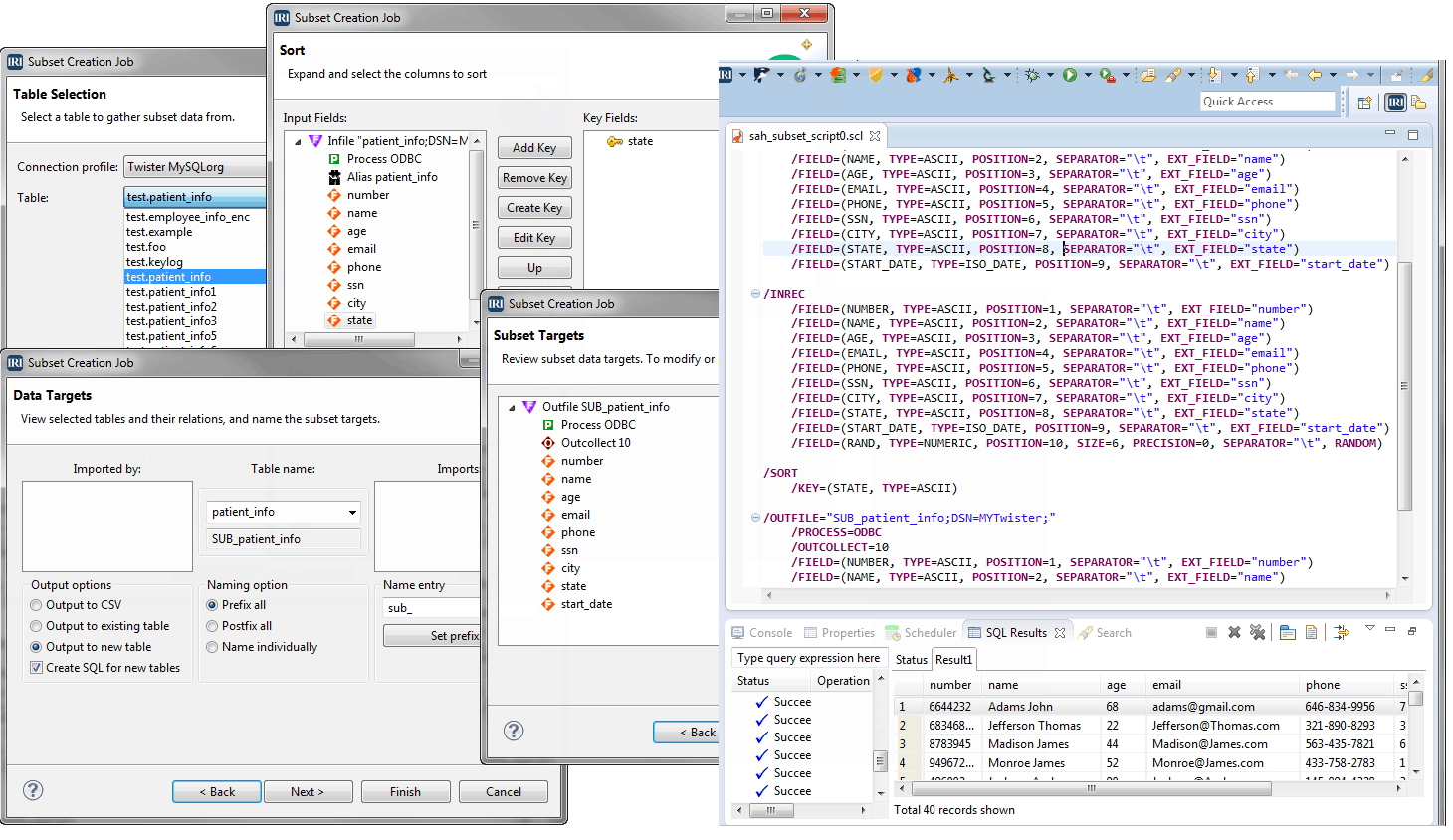
Subsetting minimiert nicht nur das Risiko von PII-Exposition und Datenschutzverletzungen, sondern senkt auch die Kosten für Datenbank- und Anwendungstest-Infrastrukturen drastisch... einige sagen bis zu 50.000€ pro Datenbank. Erfahren Sie hier, wie Sie in der Workbench Unteraufträge automatisch einrichten und erstellen.