
Beschleunigen Sie Ihr DI-Tool
Optimierung der Extraktion, Transformation und Ladeleistung
Herausforderungen
Die meisten ETL- und ELT-Tools sowie die von ihnen verwendeten Datenbankmodule können große Datenmengen nicht effizient transformieren ohne:
· eine teure Parallelverarbeitungs-Edition
· Entnahme von Datenbank- oder Systemressourcen von Dritten
· eine komplexe, schwer zu wartende Hadoop-Umgebung
· eine 6 oder 7-stellige Hardware-Appliance oder Server-Upgrades
· das Problem auf eine noch teurere Datenbank zu übertragen
Es sind die großen Sortier-, Joint- und Aggregationsaufträge, die zu lange dauern können. Auch nachfolgende Aufgaben wie das Laden, Analysieren oder BI-Displays leiden. Und diese E-, T- und L-Schritte werden typischerweise in separaten Schritten, I/O-Durchgängen, Produkten oder ständig wechselnden Cloud-Konfigurationen durchgeführt.
Lösungen
Wenn Sie andere ETL- oder ELT-Software verwenden, können IRI-Extraktions- und Transformationsprogramme wie FACT oder CoSort - oder die IRI Voracity ETL- und Datenmanagement-Plattform, die sie unterstützt - innerhalb anderer ETL-Tools ausgeführt werden, die auf Unix-, Linux- oder Windows-Hardware laufen.
|
Operation |
IRI Produkt |
Ünterstützung |
Vorteile |
|
IRI FACT (Fast Extract) |
Oracle, DB2, Sybase, MySQL, SQL Server, Altibase, Greenplum, Teradata, Tibero |
Native DB-Treiber, paralleles Entladen, tragbare Flat-File-Ausgabedaten, einfache Jobskripte, einfach aufrufbar |
|
|
IRI CoSort oder IRI Voracity |
DB-agnostisch, alle Flat Files, Informatica, DataStage und alle Aufrufe von 'system command'. |
Multi-Threading, Aufgaben- und I/O-Konsolidierung, lokale und entfernte Ausführung in LUW-Dateisystemen oder Hadoop, sowie automatische Metadaten und Joberstellung. |
|
|
Alle RDBMS-Lader, ODBC und JDBC |
Streaming vorkoordinierter Daten nach E- oder T-Aufträgen zur Reduzierung der Ladezeit um bis zu 90%. |
||
|
Mehr als 125 alte und moderne kleine und große Datenquellen und Ziele. |
Alle oben genannten in einer umfassenden Datenverwaltungsumgebung, die Datenerfassung, -integration, -migration, -steuerung und -analyse in Eclipse kombiniert. |
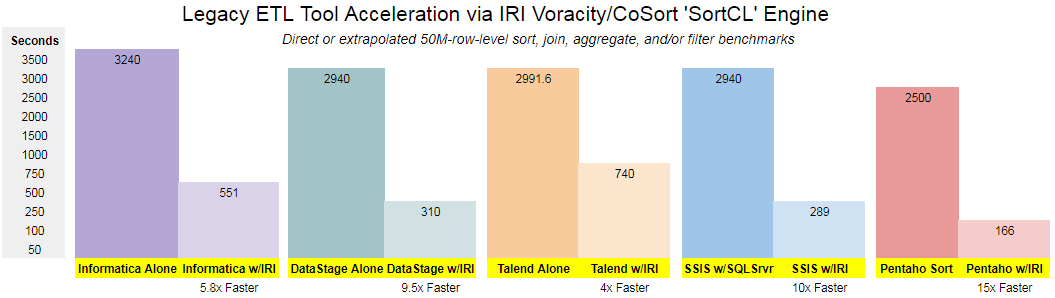
Optimieren Sie Sortier-, Joint- und Aggregationstransformationen in Inormatica, DataStage, Talend, Pentaho, ODI und anderen Tools mit der SortCL-Engine im CoSort Produkt oder der Voracity-Plattform. Viele SortCL-Aufträge können auch nahtlos in Hadoop ausgeführt werden und werden mit anderen Tools auf API- oder Skriptebene aufgerufen, z.B. in Kalido, ETI, Software AG Natural, SAS und TeraStream.
Verwenden Sie die Metadaten und Workflows die Sie haben und rufen Sie die IRI-Software einfach von Ihrem Tool aus auf, um die Geschwindigkeit zu erhöhen und/oder Entladen, Datentransformationen und Operationen wie:
· Sortierungen
· Joins
· Aggregate
· Lookups
· Perl-kompatible reguläre Ausdrücke
· Datentyp- und Dateiformatkonvertierungen
· Feld-/Spaltenverschlüsselung und Maskierung
· Detail-, Delta- (CDC) und Summenberichte
· Pivoting von Zeilen und Spalten
· Slowly Changing Dimensions
· Generierung von Testdaten
Sie können IRI-Jobs auch von der Shell aus (als Batch-Ausführung oder ETL-Tool-Befehl) über API oder Eclipse GUI aufrufen und Daten bei Bedarf über Dateien, Pipelines oder Prozeduren hin und her fließen lassen. In der GUI-Umgebung der IRI Workbench können Sie die einzelnen Job-Spezifikationen oder komplette ELT- oder ELT-Flüsse erstellen, die CoSort (und FACT) mit Ihren Quellen und Zielen verbinden.
Erwin (AnalytiX DS) und Meta Integration Model Bridge (MIMB) Software oder Dienste können auch Metadaten, die in gängigen ETL-Tools (wie Informatica's.xml und DataStage.dsx Repositories) definiert sind in gleichwertige Voracity-Daten- (und/oder Job-) Spezifikationen konvertieren, wenn Sie diese Mappings in Voracity umplatzieren möchten um Geld und Zeit zu sparen. Diese automatische Metadatenreplikation bewahrt Ihre bestehenden Designinvestitionen, erleichtert die Schaffung von Arbeitsplätzen und reduziert die Migrationskosten.
Andere Ressources