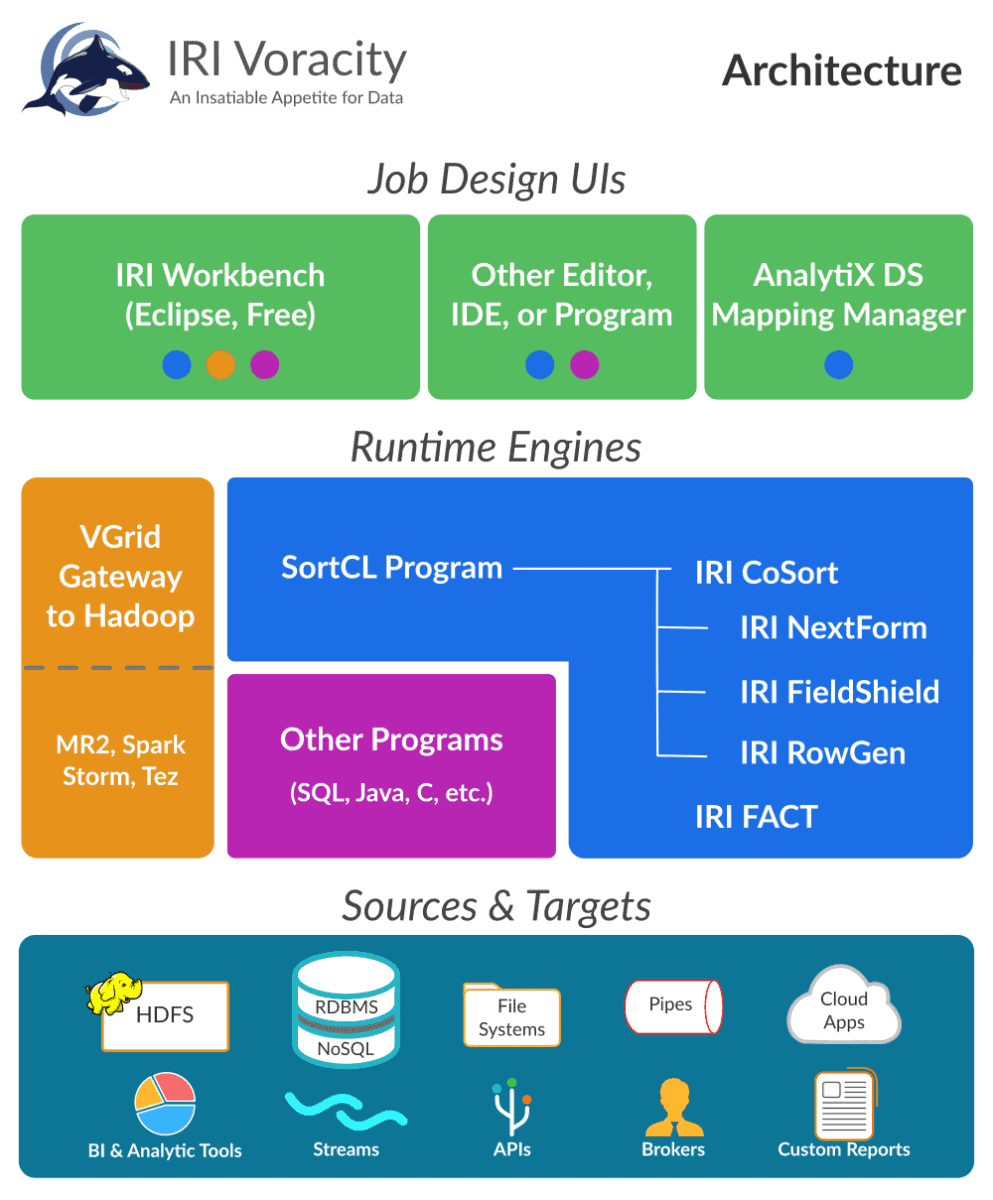
Einmal zuordnen, überall einsetzen
Verwenden Sie CoSort oder Hadoop: Gleicher Auftrag, Metadaten, GUI
Ob Hadoop oder nicht - Die Wahl ist einfacher als Sie denken.
Um große Datenmengen zu manipulieren denken die meisten Menschen, dass sie eine neue IT-Struktur wie Hadoop oder Teradata, eine In-Memory- oder Columnar-Datenbank wie SAP HANA oder Vertica, eine DB- oder ELT-Appliance wie Exadata oder Netezza oder ein komplexes ETL-Tool wie Informatica oder Ab Initio benötigen. Haben Sie die Zeit, das Geld und die Expertise dafür?
Was wäre, wenn es eine einfachere und kostengünstigere Plattform für die schnelle Verarbeitung und Verwaltung großer Datenmengen gäbe, die bestehende Dateisysteme und HDFS-Daten und Engines austauschbar nutzt? Es gibt eine!
Unabhängig davon, ob sich Ihre Datenquellen in einem Standard Unix-, Linux- oder Windows-Dateisystem, in HDFS oder in den oben genannten proprietären Systemen befinden, können Sie diese Daten in der IRI Voracity-Plattform entweder mit der bewährten IRI CoSort Engine oder Hadoop Engines austauschbar verarbeiten. Ohne zu programmieren oder etwas zu ändern, teilen sich Ihre Aufträge die gleiche einfache, zugängliche Metadatenschicht und eine kostenlose Eclipse-IDE zur Verwaltung mit grafischen Jobdesign- und Ausführungsmodi, der IRI Workbench.
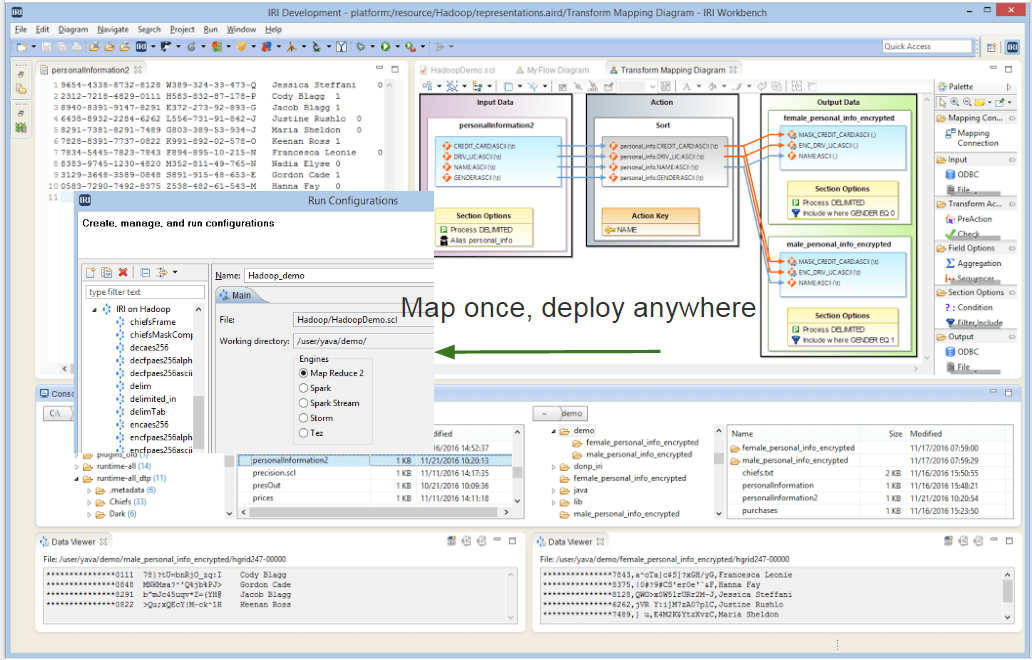
Wie wollen Sie große Daten-Workloads multiplizieren?
Klicken Sie um die nahtlosen Verarbeitungsoptionen zu sehen, die nur IRI Voracity für die Transformation, Maskierung und Generierung großer Datenmengen bietet:
Mit Hadoop
IRI Voracity nutzt die Leistung, Skalierbarkeit, den Lastausgleich und die automatische Ausfallsicherung von MapReduce 2 (MR2), Spark, Spark Stream, Storm oder Tez. Voracity führt die meisten CoSort (SortCL)-Aufträge in diesen Engines je nach Verfügbarkeit und Bedarf aus. Voracity funktioniert in Cloudera-, HortonWorks- und MapR-Distributionen. IRI wird auch eine eigene Hadoop-Distribution vor Ort oder in der Cloud und später in einer Hardware-Appliance bereitstellen, die alles beinhaltet. Dieser Artikel zeigt, wie Sie Voracity-Aufträge in Hadoop ausführen können.
Ohne Hadoop
IRI CoSort Jobs, die allein oder innerhalb von Voracity-Plattformprojekten laufen, bieten Ihnen eine 40-jährige bewährte Alternative zu Hadoop für eine schnelle, intuitive, kostengünstige und unterbrechungsfreie Datenmanipulation. Es schließt die Qualifikationslücke und die Supportkosten von Hadoop aus und benötigt nicht die Zeit, das Geld oder die Arbeitskraft, die andere Systeme benötigen die mit großen Datenmengen arbeiten. CoSort ist eine kostengünstige, ausfallsichere und risikoarme Option, die für kleine und mittlere Unternehmen oder Unternehmensteams unerlässlich ist, die ihre Multi-Terabyte-Verarbeitungsleistung lieben.
Mit Voracity geht es nicht mehr nur um homogene Daten die heterogen verarbeitet werden, oder umgekehrt. Es geht um eine nahtlose, einheitliche, metadatengesteuerte Unternehmensinformationsarchitektur, die Ihnen die Kontrolle über verschiedene Datenquellen und Verarbeitungsmaschinen gibt.... und eine, die den sich ändernden Anforderungen an Datenintegration, Governance und Analyse gerecht wird.
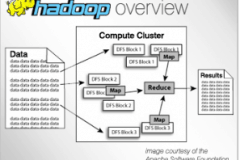
Was ist Hadoop?
Hadoop ist eine immer beliebtere Computerumgebung für die verteilte Verarbeitung, mit der Unternehmen große Datenmengen analysieren und speichern können.

Eine große Datenkrise
Große Datenmengen wachsen exponentiell und Hardware einfach darauf zu werfen, ist keine vollständige oder zuverlässige Langzeitlösung. Die bewährten Strategien und Software von IRI sind es jedoch.
Wann sollte man Hadoop verwenden?
Hadoop ist kein einheitliches Framework. Man muss wissen, wann und wie man es benutzt. Voracity macht Hadoop Jobdesign und -bereitstellung zu einem Kinderspiel, wenn Sie es brauchen.

Sehen Sie auch
Geschwindigkeit mit Velocity annehmen
DBTA-Artikel, der die Geschwindigkeit von IRI Voracity analysiert.
{kind=link}