Big Data Analyse Tools - Big Data vorbereiten und schützen
Schnellere Datenmanipulation, mit Hadoop oder nicht
Big Data Analyse Software - Können Sie Ihre Daten so einfach scannen, analysieren und schützen?
Um große Datenmengen zu gewinnen, müssen Sie sie zuerst schmelzen. Hadoop-Distributionen und Spezialsoftware können nicht alle benötigten Daten erfassen, klassifizieren oder transformieren, sie effizient zerlegen oder formatieren oder sie ordnungsgemäß weiterverarbeiten (z.B. validieren, bereinigen, maskieren, auditieren). Die Big Data Analyse Tools in der IRI Voracity-Plattform - angetrieben von IRI CoSort of Hadoop Big Data Manipulation Engines - können es. Voracity kombiniert Datenerkennung, Integration, Migration, Governance und Analytik in einer vertrauten Glasscheibe, die auf Eclipse™ basiert. Alles mit Hilfe von Big Data Analyse.

Verarbeiten, schützen und bereitstellen
Nutzen Sie Voracity, um Rohdatenquellen in HDFS oder mit Ihrem normalen Linux-, Unix- oder Windows-Dateisystem zu integrieren, zu erweitern und zu transformieren. Maskieren, verschlüsseln, pseudonymisieren, de-ID, Hash, tokenisieren, etc. Sie die Daten, während Sie sie transformieren und bereitstellen. Bereiten Sie Daten besonders für Big Data Analyse Tools schneller auf, um tiefergehende Einsichten zu ermöglichen, die über traditionelle BI/Analyse-Tools hinausgehen. Generieren Sie Testdaten, entwerfen Sie benutzerdefinierte statistische Berichte oder füttern Sie BIRT, R, KNIME oder Splunk im Speicher.
Die Power die Sie brauchen
Wählen Sie zwischen der Verarbeitung von Multithread-Dateisystemen in der bewährten IRI CoSort Engine oder führen Sie die gleichen Jobs in MR2, Spark, Spark Stream, Storm oder Tez in HDFS aus. Manipulieren Sie große Datenmengen mit dem gleichen Eclipse™ Jobdesign und der gleichen verwalteten Metadateninfrastruktur, um sie für fortschrittliche Big Data Analyse Tools vorzubereiten. Diese Tools ermöglichen es Ihnen, aus Ihren Daten tiefgreifende Erkenntnisse zu gewinnen und komplexe Analysen durchzuführen.
Unterschiedliche Arten von Daten
Voracity-Benutzer arbeiten mit der ganzen Welt der großen und kleinen Daten. Das heißt, Quellen und Ziele, die sich in strukturierten, semistrukturierten und unstrukturierten Formaten in Dateien und Datenbanken befinden, die sich vor Ort oder in der Cloud befinden. Nutzen Sie Voracity, um alle Ihre Daten zu mischen und mit fortschrittlichen Big Data Analyse Tools zu untersuchen. Diese Tools ermöglichen es Ihnen, tiefere Einblicke zu gewinnen, Daten zu entdecken, zu maskieren und zu bereinigen, um Zuverlässigkeit und Compliance zu gewährleisten.
Ganzeinheitlicher Einblick
Erstellen, Ausführen und Verwalten Ihrer Datenentdeckungs-, Integrations-, Migrations-, Governance- und Analyseaufgaben in den von Ihnen gewählten Designmodi.... alles in derselben, kostenlosen, grafischen Eclipse™ IDE for Voracity, IRI Workbench. Teilen, Versionskontrolle, Sichern und Ausführen der Aufträge aus der GUI, Batch-Skripten, Anwendungen oder verteilten Computerumgebungen wie Hadoop für mehr Geschwindigkeit und Skalierbarkeit.
Überraschend erschwinglich
Ihre Fähigkeit große Daten zu verarbeiten, erfordert nicht mehr ein großes Budget für Hardware, Software oder eine Armee von Hadoop-Geeks. Die Voracity-Datenmanagement-Plattform von IRI aus einer Hand wird schnell große Mengen an privaten und öffentlichen Daten verarbeiten.... alles zu niedrigen Abonnement- oder Prepetual Use-Preisen, die KMU- und kostenbewusste Enterprise CFOs bevorzugen.
Die großen Datenvorteile und Bona Fides von Voracity
Seit mehr als vierzig Jahren ist IRI der bewährte Produktionspartner für die Vorbereitung und Präsentation massiver, multipler Datenquellen über Branchen, Regionen und Unix/Windows-Plattformen hinweg. Finden Sie heraus, was Sie brauchen:
ein erschwingliches Produkt, die IRI Voracity-Plattform, die Daten entdeckt, integriert, migriert, steuert und analysiert, alles in allem:
ein einfacher Ort, eine kostenlose Eclipse-GUI, die ein einfaches 4GL unterstützt, und
ein I/O-Pass, der Datentransformation, Schutz und Reporting kombiniert.
Hier ist, was mit Voracity machbar ist:
Big Data Verarbeitung - integrieren (suchen, erfassen, verbinden, etc.), bereichern (bereinigen, umwandeln, berechnen, etc.) und transformieren (filtern, sortieren, aggregieren, etc.) in HDFS oder mit Ihrem Dateisystem.
Big Data Schutz - maskieren, verschlüsseln, pseudonymisieren, de-ID, hashen, tokenisieren, etc. von Daten, während Sie sie transformieren und bereitstellen.
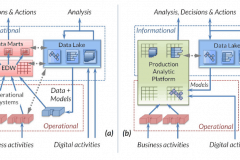
Big Data Bereitstellung - Massenladung mit vorsortierten Daten, Erstellung von Replikaten und föderierten Ansichten, Aufbereitung (Blending, Munging) von Daten für BI/Analysetools, Schreiben von Berichten, Feeds BIRT oder Index Splunk direkt oder Erstellung großer Testdaten. Der Data Warehouse Experte Barry Devlin nennt Voracity als eine prozessanalytische Plattform.... erfahren Sie warum.
Voracity und alle konstituierenden IRI-Produkte verwenden alle das gleiche selbstdokumentierende 4GL-Programm von IRI CoSort namens SortCL für die Datendefinition, Manipulation, Maskierung und Berichterstattung.
Gestalten und verwalten Sie Ihre Jobs in einer Vielzahl von Benutzeroberflächen einheitlich. Teilen, Versionen kontrollieren, sichern und ausführen der Aufträge in Eclipse oder integrieren Sie sie in Batch-Skripte, Anwendungen oder verteilte Computerumgebungen wie Hadoop für noch mehr Geschwindigkeit und Skalierbarkeit.
Durchsuchen Sie diesen Abschnitt und seine Links für weitere Details, sehen Sie hier wer Voracity als großen Datenführer erkennt und fordern Sie hier eine Live-Demo oder eine kostenlose Testversion an.
Wussten Sie?
- Voracity verwendet CoSort oder Hadoop-Engines und CoSort vordatiert große Datenmengen in Hadoop, wobei die Technologie seit 1978 in Entwicklung ist? IRI verwendet den Begriff "Big Data" seit 2004 in CoSort-Anwendungen in Telco CDR Data Warehousing-Projekten auf Multi-Core- oder verteilter Hardware und lange zuvor in anderen Transaktionsdateien der Branche (Banken und Behörden).
- CoSort das typischerweise für Datentransformation, Staging und Reporting verwendet wird, kann auch das tun, was Spin-offs tun: Datenmigration (IRI NextForm), Datenmaskierung (IRI FieldShield) und Testdatengenerierung (IRI RowGen).
- IRI Voracity verwendet die gleichen Metadaten und Eclipse™ GUI (IRI Workbench) wie CoSort und die Spin-offs ermöglichen Ihnen auch das Design und die Planung von Aufträgen mit dem neuesten ETL-Workflow und integrierte Automatisierungstools.
- Voracity Benutzer können in der GUI der IRI Workbench ihre HDFS-Dateien und -Inhalte ansehen, Daten zu und von HDFS übertragen und Ihre Transformations- und Maskierungs-Jobskripte (und Batchflows) automatisch konvertieren. Die Ausführung im Dateisystem oder in HDFS kann bei Bedarf gesteuert oder in derselben GUI geplant werden, in der Sie Ihre Aufträge und Metadaten entwerfen und verwalten.
Big Data Analyse Tools - Ressourcen