
R-Analytik Beschleunigung
Vorbereitung großer Datenmengen und Ausführen von R in Eclipse
R ist eine freie Programmiersprache und Softwareumgebung, die Statistiker und Data Miner für Analysen und Vorhersagen verwenden und ist als Visualisierungswerkzeug für große Datenmengen bekannt geworden. Da R jedoch alle seine Objekte im Speicher hält, kann es nicht effektiv mit sehr großen Datensätzen arbeiten.
Das SortCL-Programm in der IRI Voracity Big Data Management Plattform oder dem eigenständigen IRI CoSort Paket ist eine schnelle, einfache und kostengünstige Möglichkeit, große Daten für R effizient aufzubereiten - sowohl in Bezug auf Jobdesign als auch auf die Laufzeitperformance.
Als wir einen SortCL-Sortier-, Join- und Aggregationsauftrag vor (und statt) R ausgeführt haben, wurden die Time-to-Visualisierungen in Tools wie ggplot oder qplot halbiert:
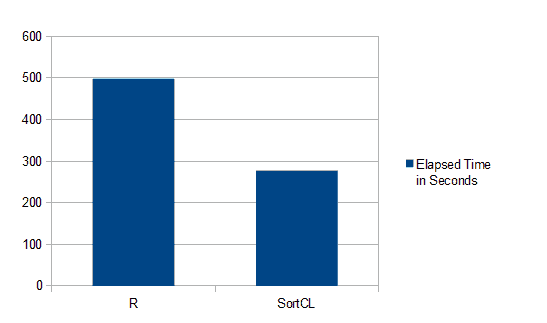
R arbeitet nur mit mehreren kleinen Datenblöcken und benötigt mehrere Code-Dateien, um das gleiche Ergebnis wie ein einzelner SortCL-Job zu erzielen. Hadoop ist eine weitere Möglichkeit, große Datensätze schnell für R vorzubereiten und Voracity-Benutzer können die meisten SortCL-Aufträge nahtlos in Map Reduce 2, Spark, Spark Stream, Storm oder Tez ohne zusätzliche Programmierung ausführen.
Weitere Informationen zum Benchmark und wie SortCL Daten in derselben Eclipse-Umgebung aufbereiten kann (über das StatET für R Plug-in für IRI Workbench), finden Sie hier.