
Accelerating R Analytics
Prepare Big Data and Run R in Eclipse
R is a free programming language and software environment that statisticians and data miners use for analysis and predictions, and has become known as a 'big data' visualization tool. Because R holds all its objects in memory, however, it cannot effectively work with very large data sets.
The SortCL program in the IRI Voracity big data management platform or standalone IRI CoSort package is a fast, simple, and inexpensive way to prepare big data for R efficiently -- both in terms of job design and runtime performance.
When we ran a SortCL sort, join, and aggregation job ahead (and instead) of R, time-to-visualizations in tools like ggplot or qplot were cut in half:
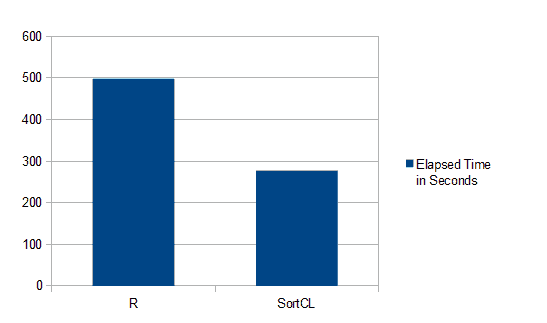
R works only on multiple, small chunks of data, and requires multiple code files to produce the same result as one a single SortCL job. Hadoop is another way to rapidly prepare big data sets for R of course, and Voracity users can run most SortCL jobs seamlessly in Map Reduce 2, Spark, Spark Stream, Storm, or Tez without additional coding.
For more information on the benchmark and how SortCL can prepare data in the same Eclipse environment (via the StatET for R plug-in for IRI Workbench), klick here.