
OBIEE Acceleration
Speed Time-to-Visualization and Unburden Oracle
Oracle Data Visualization (DV) and Oracle Business Intelligence Suite, Enterprise Edition (OBIEE) are advanced BI solutions using Oracle as the backend database for staging visualizations like these:
Processing high volumes of data in Oracle, however, is inherently less inefficient than processing them in a faster external data wrangling engine. Oracle is designed for storage and retrieval, not the huge transforms that necessitate complex tuning and continual hardware upgrades -- or costly alternatives like Exadata or Hadoop.
Thus, rather than taxing Oracle users or shifting to appliances or other risky fabrics to accelerate and inefficient architecture, consider centralizing your BI data preparation in the file system you have. Central data preparation frees the DB from repeated transformation activities, and frees BI users from the burden of data integration for every report job. The same logic holds true for Oracle Data Visualization (DV / Desktop) and other BI tools.
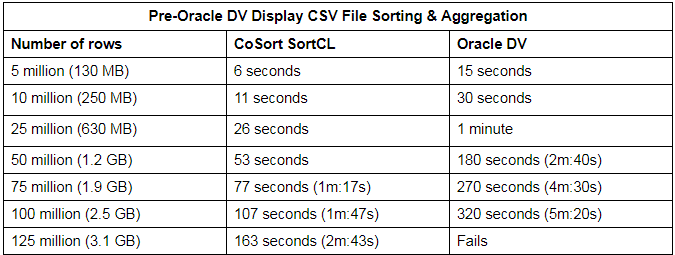
Core components in the IRI Voracity data mangement platform, such as IRI CoSort -- and its SortCL program in particular -- are proven offline engines for Oracle (and other big data sources) table extraction, transformation, loading (ETL), and related Oracle data management. SortCL's numerous data transformation functions run much faster outside Oracle - either in the file system or Hadoop. Robust data masking and test data generation are also a part of this environment. In fact, you can combine data manipulation in masking as you prepare data for presentation.
Beyond versatility and velocity is ease-of-use. SortCL's 4GL job scripts are far simpler and smaller than PL/SQL procedures, and they can be auto-created, deployed, and managed from a free, familiar Eclipse GUI. Both IT (ETL) and BI users find SortCL to be a simpler way to make data ready for reporting and analysis.
See this article about the benefits of centralized data wrangling (or blending) for BI, using the example of Oracle DV. Consider how much sooner you can produce reusable tables and files from big data that's prepared externally, without affecting query performance.