
Data Federation / Virtualization
Get Instant Information from Disparate Sources
Data Federation virtualizes, rather than integrates, disparate data sources to produce immediate, fit-for-purpose information views. Data federation bypasses the normal ETL overhead of physical data consolidation, replication, and relational database population.
"When users simply need unified, near-real-time, on-demand access to data that originates in many source applications, data federation is an attractive alternative. Information and knowledge management (I&KM) professionals should also consider data federation a complementary approach that can extend and enrich their current EDW environment.”
Forrester Research
IRI's approach to abstracting and leveraging heterogeneous sources is unconventional, simple, and very affordable. There is no extra cost for IRI Voracity platform or IRI Data Manager suite users to produce ad hoc information from siloed data sources. And, if you use the Lite version of IRI NextForm to create ad hoc data view from flat files, the software is free. Affordable versions of NextForm, and IRI CoSort, also support database connections.
Rather than creating new middleware, a federated database, or application layer, data federation occurs in the same place ETL and BI do - in the IRI Workbench GUI, built on Eclipse™.
Get discrete solutions and generate immediate information through SQL queries, or create custom CoSort SortCL programs to filter, join, standardize, and report from disparate DB and flat file sources. Define new schemas, master data values, format masks (composite data types), and custom report targets in multiple SortCL outputs simultaneously. Send results to the console or temporary tables for unstored what-if analyses.
IRI's data federation approach also supports:
- easy table and file data discovery, with automatic metadata creation
- an agile query environment allowing what-if analyses and reiteration
- fast results from tactical scripting and big data movement power
- useful BI through cross-calculation, functions, and derived fields
- protection of source or abstracted data via field masking, encryption, etc.
- data quality through enrichment, cleansing, and third-party libraries
- standard and complex data transformations at the field-level
- "data-less" test data generation using original or federated metadata
- ad hoc data contributions to ETL tool and analytic platforms
- population of federated data to data services (in development)
Unifying Processing and Information
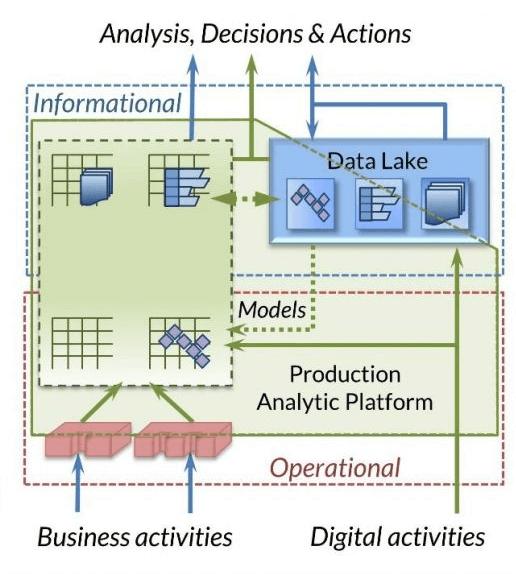
Click here to see an example of how to federate data quickly and easily in the IRI Workbench, using any of the back-end engines above.