Big Data Provisioning
Franchise and Deliver Data for Decisions
Big Data Provisioning
Provisioning big data for meanginful use is the next step in creating actionable information.
As it packages and protects data, IRI Voracity data management platform can produce multiple batch or real-time targets at once, including:
- ODS, DW, and data mart DBs (pre-sorted)
- flat files for use in ETL tools, ELT appliances, and Hadoop
- piped, procedure, or brokered (MQTT/Kafka) in-memory data feeds
- 2D reports, federated views, or BIRT charts in Eclipse
- predictive analytic, data science, machine learning, and deep learning (AI) nodes in KNIME
- data wrangling for BI, data mining, and analytic tools like Cognos, OBIEE, Power BI, QlikView, R, Spotfire, Splunk, and Tableau
- masked production or synthetic test data targets
Voracity externalizes data preparation and provisioning in Unix, Linux, and Windows file systems or HDFS ... whatever you've configured will now be a faster, more cost-effective place to stage and scale your big data processing operations.
Prepare Data for Predictive analytic: BDQ Big Data Quarterly article from DBTA
Succeeding with data science and machine learning, learn more in the BDQ Big Data Quarterly article from DBTA here.
"Voracity also offers a simplified form of data virtualization, allowing direct access by business people to the ultimate source of data. Because a single set of common metadata supports both virtualization and off-line processing, the alignment of cleansing and integration in different time frames is more easily achieved." Dr. Barry Devlin - 9sights consulting
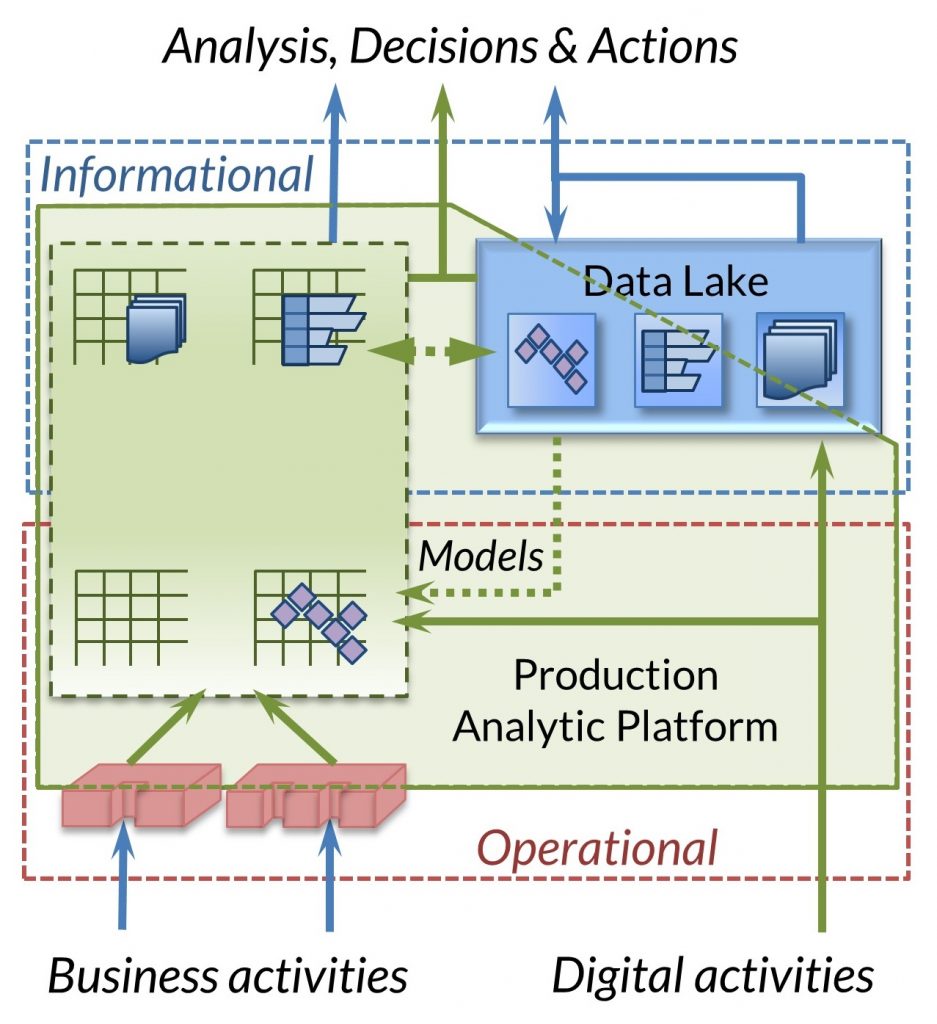
At the same time, Voracity's simple, centralized metadata separates your data from your applications and becomes a Production Analytics Platform, which means:
No Impact on Production. Major Time and Cost Savings!
- Remove the heavy lifting of transformation from production database, application, and BI tools/layers
- Provide clean, secure, and pre-formatted data through files, tables, pipes, and procedures to the targets that need that data, when they need it
- Prevent the storage and synchronization problems associated with using multiple copies of data
- Surgically select and insert data using SQL-compatible /QUERY and /UPDATE commands inside SortCL jobs to drive data flows according to business rules
- Improve insight quality with fresher data
- Run your jobs on any platform, and on schedules subject to conditions you define and automate. Avoid the usual data warehouse and data mart update delays associated with manual provisioning