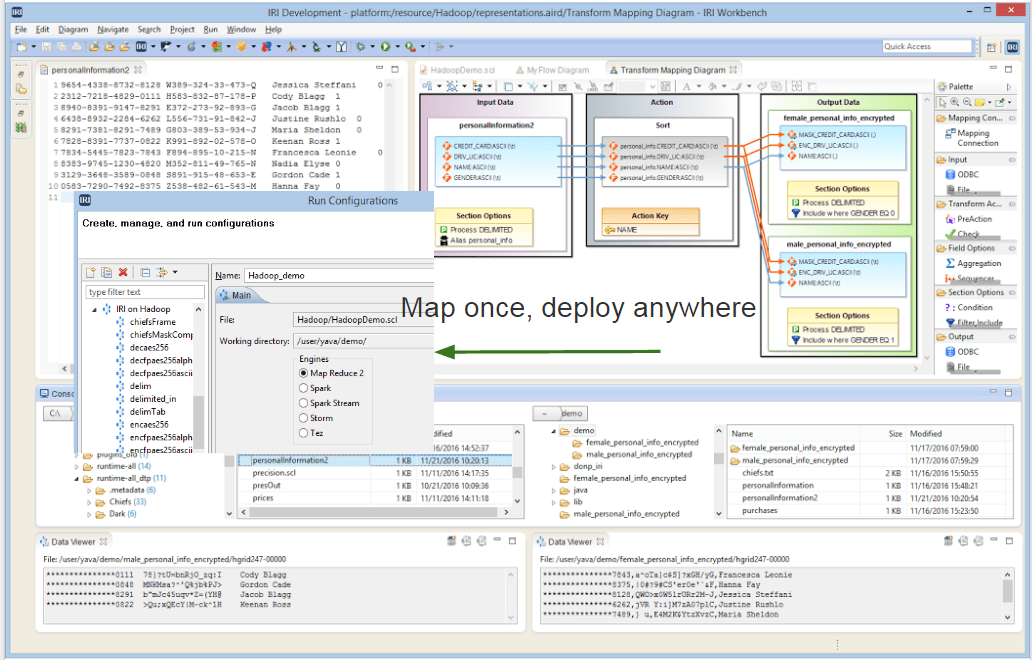
Map Once, Deploy Anywhere
Use CoSort or Hadoop: Same Job, Metadata, GUI
To Hadoop or Not - The Choice is Easier Than You Think
To manipulate big data, most people think they need a new IT fabric like Hadoop or Teradata, an in-memory or columnar database like SAP HANA or Vertica, a DB or ELT appliance like Exadata or Netezza, or a complex ETL tool like Informatica or Ab Initio. Do you have the time, money and expertise for them?
What if there were a simpler and more affordable fast processing and governance platform for big data that exploited existing file system and HDFS data and engines interchangeably? There is!
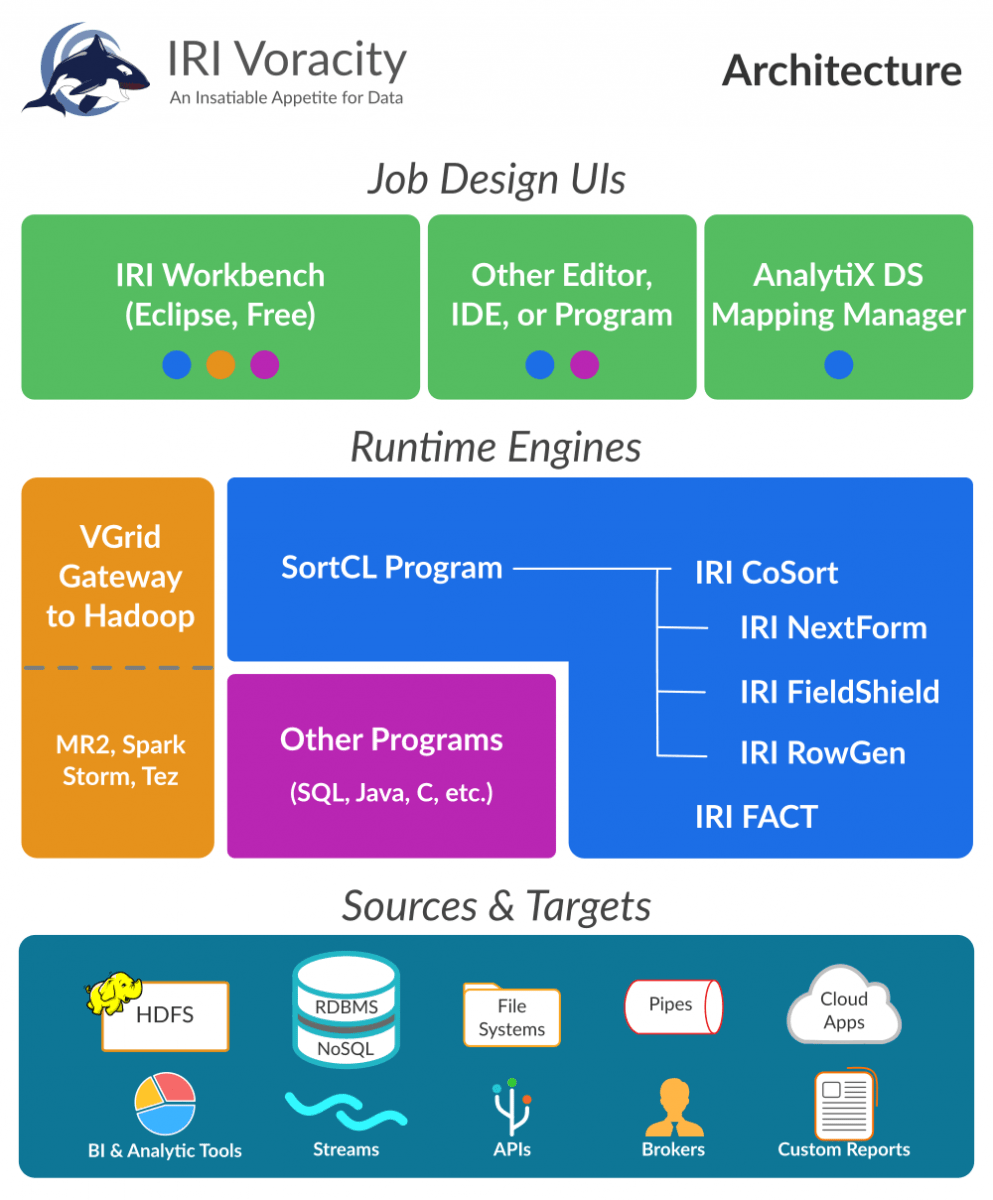
Whether your data sources are in a standard Unix, Linux or Windows file system, in HDFS, or managed in the proprietary systems above, you can process that data in the IRI Voracity platform using either the long-proven IRI CoSort engine or Hadoop engines interchangeably. Without coding or changing anything, your jobs share the same simple, accessible metadata layer, and a free Eclipse IDE for managing it with graphical job design and execution modes, called IRI Workbench.
How do you want to multi-process big data workloads?
Click to see the seamless processing choices that only IRI Voracity delivers for big data transformation, masking, and generation:
With Hadoop
IRI Voracity leverages the performance, scalability, load balancing, and automatic failover capabilities of MapReduce 2 (MR2), Spark, Spark Stream, Storm, or Tez. Voracity runs most CoSort (SortCL) jobs in these engines based on availability and need. Voracity works in Cloudera, HortonWorks, and MapR distributions. IRI will also provide its own Hadoop distribution on-premise or in the cloud, and later in a hardware appliance that includes everything. This article shows how to run Voracity jobs in Hadoop.
Without Hadoop
IRI CoSort jobs running alone or inside Voracity platform projects gives you a 40-year proven alternative to Hadoop for fast, intuitive, inexpensive, and non-disruptive data manipulation. It precludes the skills gap and support costs of Hadoop, and it does not require the time, money, or manpower other systems do that work with big data. CoSort is a low-cost, low-impact, and low-risk option essential for small and medium-sized business, or enterprise line of business teams that love its multi-terabyte processing performance.
With Voracity, it's no longer a matter of homogeneous data processed heterogeneously, or vice versa. It's about having a seamless, unified, metadata-driven enterprise information architecture ... one that gives you control over different data sources and processing engines ... and one that meets changing data integration, governance, and analytic needs.
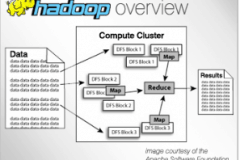
What is Hadoop?
Hadoop is an increasingly popular computing environment for distributed processing that business can use to analyze and store huge amounts of data.

A Big Data Quandry
Big data volumes are growing exponentially, and simply throwing hardware at it isn't a complete or reliable long-term solution. IRI's proven strategies and software, however, are.
When to Use Hadoop?
Hadoop isn't a one-size-fits-all framework. You need to know when and how to use it. Voracity makes short work of Hadoop job design and deployment when you need it.

See Also

{kind=link}