Data Life Cycle Management
Connect, Catalog, Consume, Change, Comply, Curate
Within its single pane of glass built on Eclipse™, IRI Voracity ® offers multiple data discovery and metadata definition tools for searching and organizing your data sources on local and remote systems.
Data life cycle management (DLCM) is the process of curating data ... from planning its requirements all the way through its use and retirement. The cycle can manifest across applications, databases, and storage media.
Data cleaning and curation is the cornerstone of modern BI pipelines. Data must first be "Cataloged" and "Connected" before it can be "Consumed" by applications and various analytic tools.
- Tamr -
From profiling existing data to defining new data types, from data mapping and masking to analytics, and from metadata management to master data management, every stakeholder can share the free Eclipse GUI for Voracity, IRI Workbench, to curate and exploit data as a team.
Following are some of the things you can do in IRI Workbench, most simultaneously:
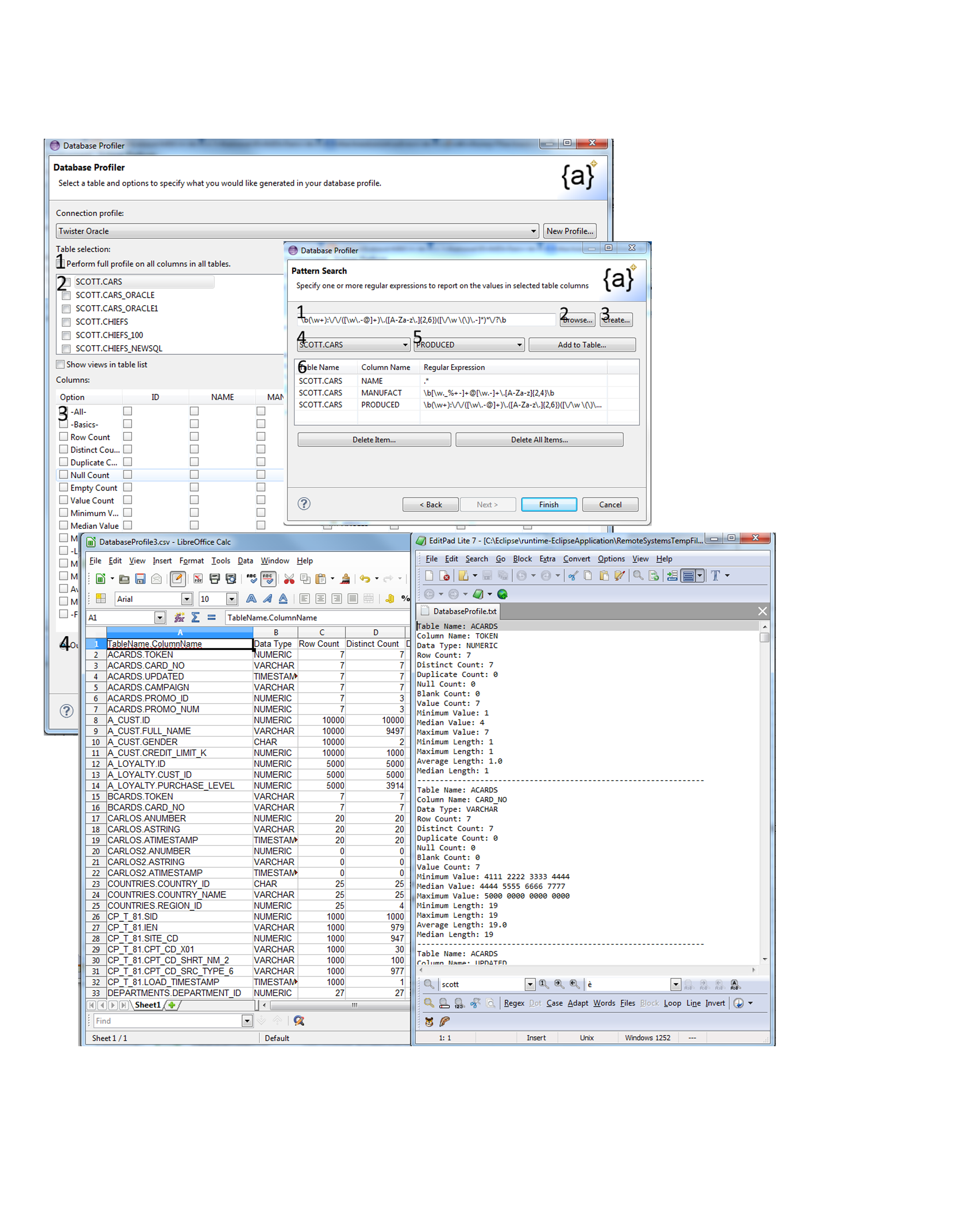
Profile & Acquire
Discover and extract data and metadata, and auto-create IRI-ready metadata as you connect to one or more of these data sources.
Use Voracity GUI support for features in CoSort (SortCL) and RowGen that define custom data structures, mask date formats, and build test data formats and values.
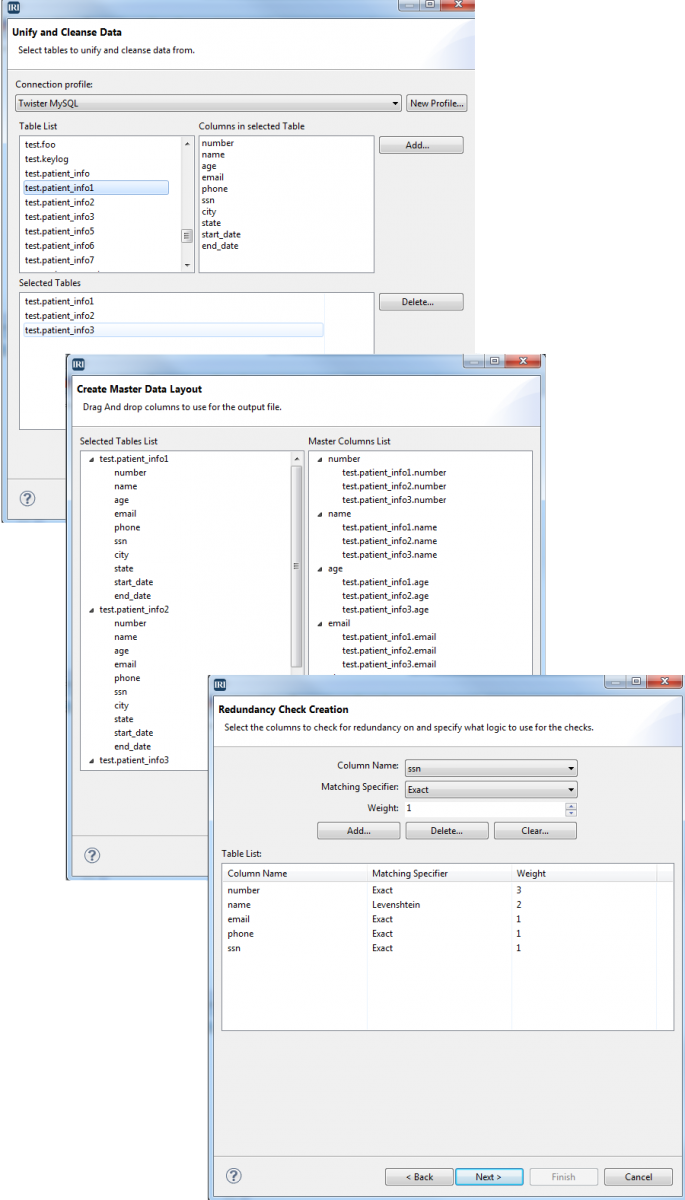
Cleanse & Unify
Use GUI-supported data quality features in the CoSort SortCL program to filter, enrich, scrub, and standardize data in multiple sources.
Use Voracity MDM modules to select, fuzzy-search, and merge reference data into master tables and values.
Protect & Audit
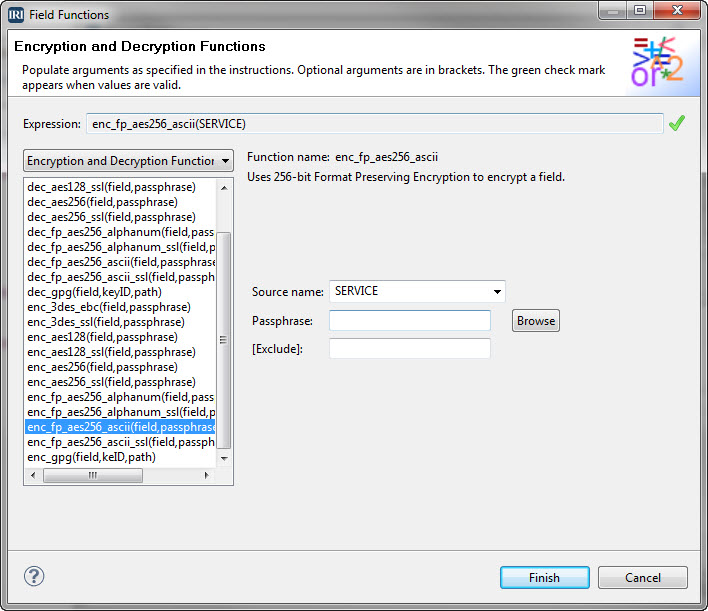
Auto-locate and classify sensitive data, and then automatically de-identify it at the field-level ... even as you filter, transform, report on it, or hand it off. Use Voracity's built-in FieldShield functions to encrypt, hash, pseudonymize, redact, tokenize, etc.
Produce an automatic XML audit log from any Voracity job for query-ready reports of the runtime environment and all protection parameters.
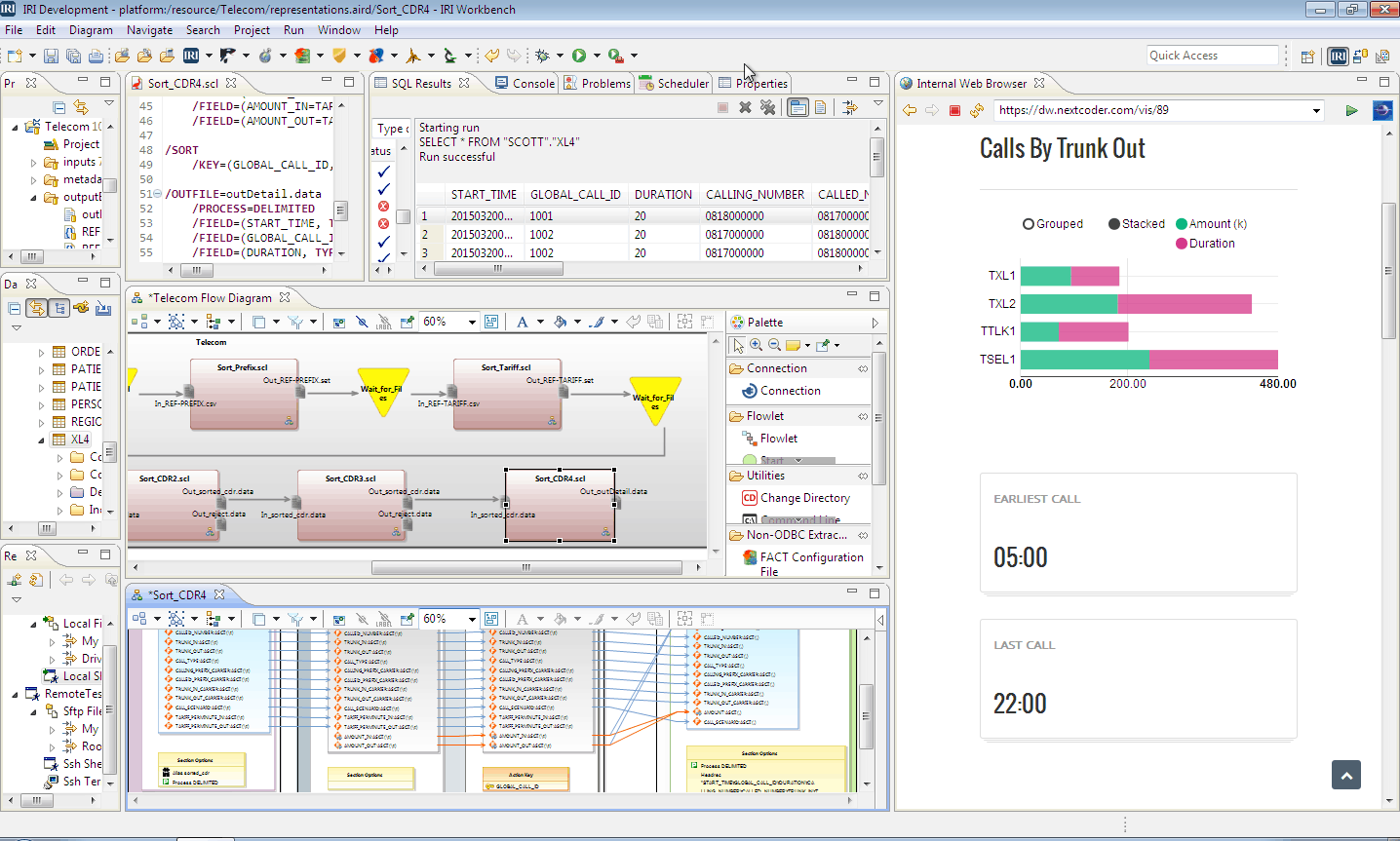
Process & Provide
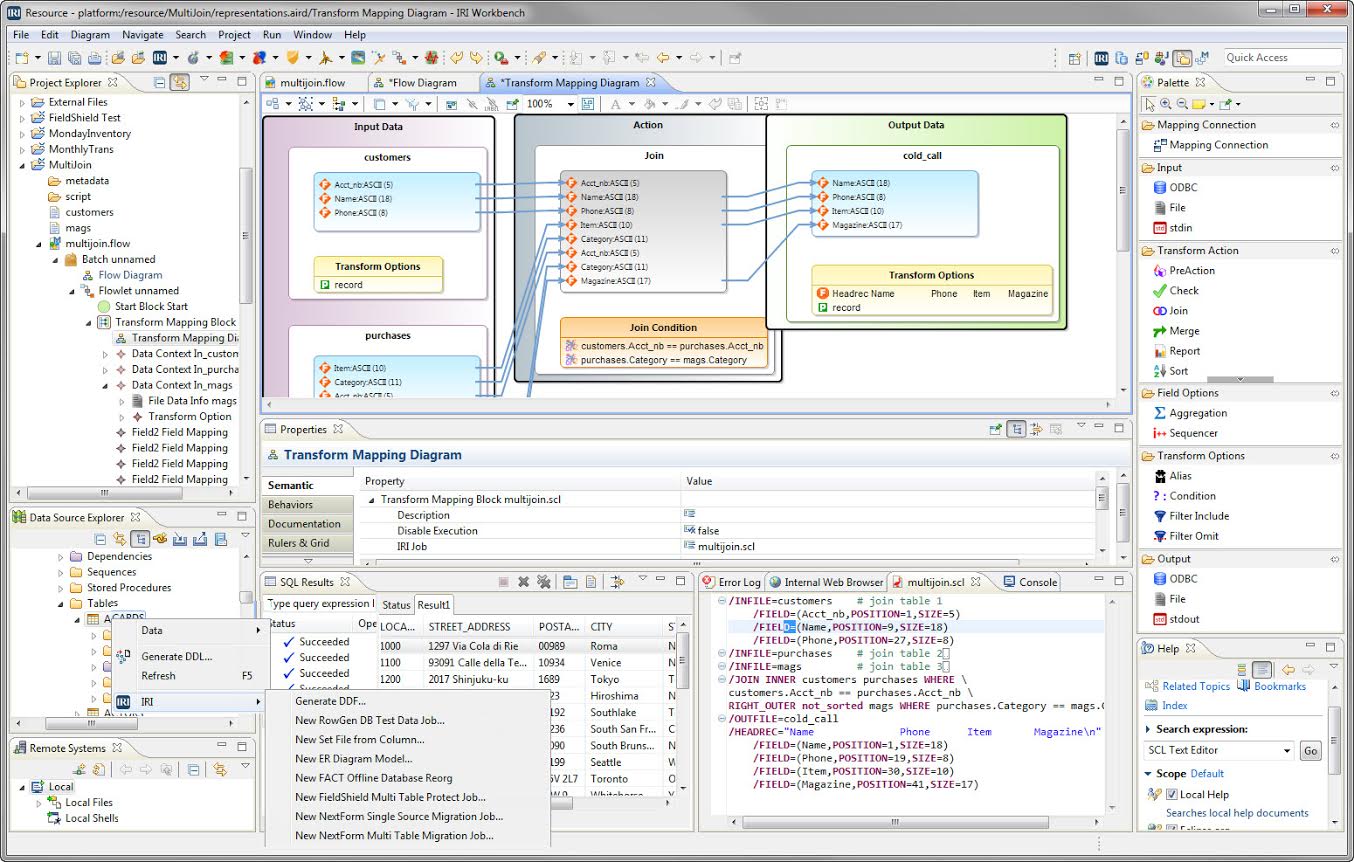
Integrate, migrate, govern, and analyze data in the same job and I/O pass using parallel CoSort (SortCL) programs or Hadoop engines, which you design and deploy in the same 'pane of glass', the Voracity GUI: IRI Workbench.
Use GUI workflow diagrams to designate and visualize any number of test or production targets in table, file, report, cube, or DB loader format.
Express & Predict
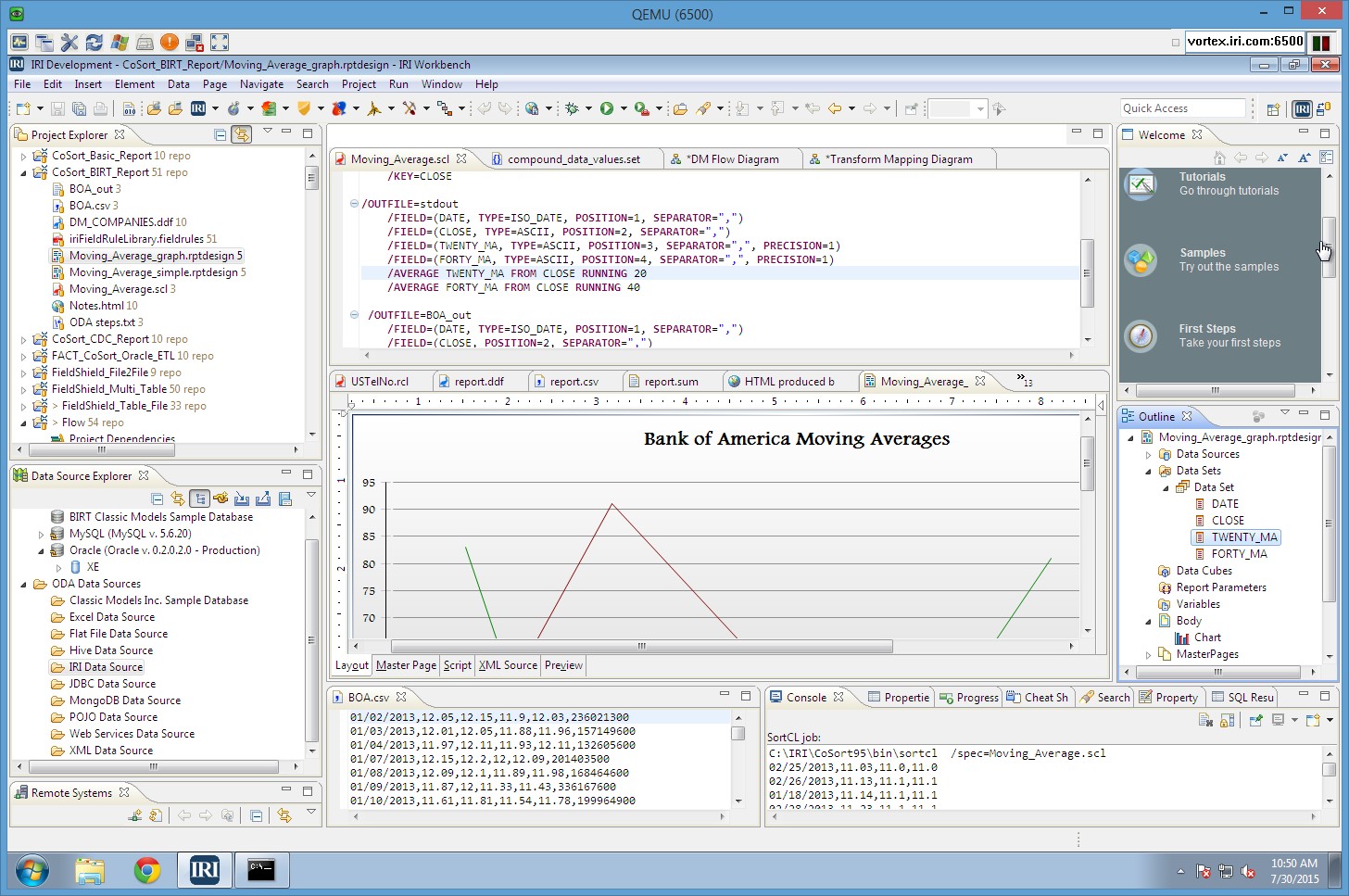
Use embedded BI features to aggregate, cross-calculate, and format data in detail, summary and trend reports, or, hand-off results to your analytic tool.
Exploit Voracity's in-memory integration with BIRT in Eclipse. BIRT consumes IRI Data Sources in its ODA driver, using stdout field names and values at reporting time.
Convert & Replicate
Use file and database migration wizards in Voracity's NextForm menu to expedite conversion of legacy data sources and data types, or simplify specify new target formats in any operation.
Create copies and subsets of data in any number of formats at once with simple GUI dialogs, or use Voracity's myriad ETL design options for more elaborate data replication.
Publish & Share
Beyond your options for directing results to federated or persistent targets, you can connect others to them in shareable repositories like EGIT, Subversion, CVS, etc.
Version-control your data and metadata, track their changes and lineage, and secure access to both in the cloud.